


html5 Validation -- unverständliche Fehlermeldung
 einsiedler
einsiedler
- zeichencodierung
nicht angemeldet einsiedler
Hallo liebe Leute,
ich verstehe diese Fehlermeldung des html5 Validators nicht!
Warning: Using windows-1252 instead of the declared encoding iso-8859-1.
http://www.tassilo.sturm.serverma.de/work.php?dir=1
Warning: Legacy encoding windows-1252 used. Documents should use UTF-8.
http://www.tassilo.sturm.serverma.de/work.php?dir=1
Error: Internal encoding declaration utf-8 disagrees with the actual encoding of the document (windows-1252).
From line 5, column 3; to line 5, column 25
↩<head>↩ <meta charset="utf-8"/>↩ <me
siehe : zum Validator Was möchte er mir sagen!
Grüsse der einsiedelnde
Lieber einsiedler,
Warning: Using windows-1252 instead of the declared encoding iso-8859-1.
zu Deutsch etwa "Warnung: Benutzt windows-1252-Enkodierung anstatt der im Dokument angegebenen ISO-8859-1-Enkodierung.
Warning: Legacy encoding windows-1252 used. Documents should use UTF-8.
Zu Deutsch etwa "Warnung: veraltete Enkodierung windows-1252 benutzt. Dokumente sollten UTF-8 als Kodierung benutzen.
Was möchte er mir sagen!
Dass Deine Angaben nicht zum Inhalt passen. Dein Dokument enthält Text (lies: HTML-Code), der in windows-1252 kodierte Zeichen enthält. Im Dokument steht aber, dass es ISO-8859-1 sein soll, was offensichtlich aber nicht stimmt, und dass Du sowieso immer und grundsätzlich eine Kodierung mit UTF-8 stattdessen benutzen solltest. Schon aus Prinzip. Weil es Fehler vermeiden hilft und ein internationaler Standard ist. Wenn auch nicht für Windows-Systeme...
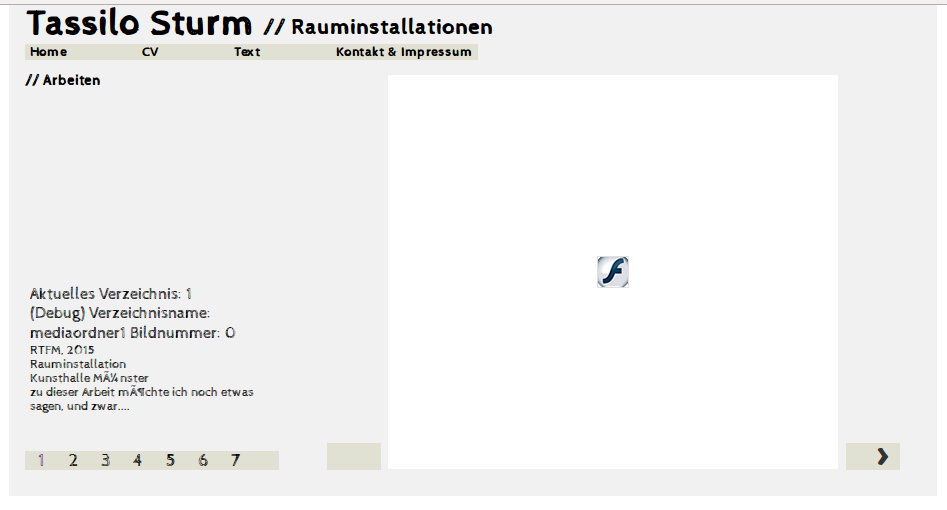
Wie Du im Screenshot sehen kannst, sollte Dich die verwendete Kodierung Deiner Dokumente kümmern.
Liebe Grüße,
Felix Riesterer.
@@Felix Riesterer
Warning: Using windows-1252 instead of the declared encoding iso-8859-1.zu Deutsch etwa "Warnung: Benutzt windows-1252-Enkodierung anstatt der im Dokument angegebenen ISO-8859-1-Enkodierung.
Nein, im Dokument ist gerade nicht ISO 8859-1 angegeben, wie die Fehlermeldung besagt.
Dein Dokument enthält Text (lies: HTML-Code), der in windows-1252 kodierte Zeichen enthält.
Nein, der in UTF-8 codierte Zeichen enthält, wie auf dem von dir gezeigten Screenshot zu sehen ist.
Im Dokument steht aber, dass es ISO-8859-1 sein soll,
Nein, das steht im HTTP-Header.
Weil [UTF-8] … ein internationaler Standard ist. Wenn auch nicht für Windows-Systeme...
Was hat Windows damit zu tun?
Ich würde denken, kein Betriebssystem nutzt intern UTF-8, sondern Codierungen mit fester Anzahl von Bytes pro Zeichen, also UCS-2 (bzw. UTF-16) oder UCS-4 (UTF-32).
UTF-8 ist die bevorzugte Zeichencodierung bei der Übertragung zwischen Systemen.
LLAP 🖖
@@einsiedler
Warning: Using windows-1252 instead of the declared encoding iso-8859-1.
Es ist iso-8859-1 als Zeichencodierung angegeben, aber da kommt wohl ein Bytewert aus dem Bereich x80 bis x9F vor, der in dieser Codierung für ein Steuerzeichen steht, also nicht vorkommen sollte. In windows-1252 liegen in dem Bereich auch darstellbare Zeichen.
Warning: Legacy encoding windows-1252 used. Documents should use UTF-8.
Du möchtest UTF-8 verwenden. Immer und überall.
Error: Internal encoding declaration utf-8 disagrees with the actual encoding of the document (windows-1252).
Der Server gibt im HTTP-Header iso-8859-1 an (s.a. W3C Internationalization Checker), vermutlich wegen Bytewerten x80 bis x9F wird das aber als windows-1252 interpretiert.
Im Dokument wird aber UTF-8 angegeben. Das passt nicht zusammen.
Wie man an „Münster“ und „möchte“ sieht, ist das Dokument tatsächlich in UTF-8 codiert. Es wird aber nicht so decodiert, weil die Angabe im HTTP-Header Vorrang vor der meta-Angabe im Dokument hat.
Sorge dafür, dass dein Server entweder auch die richtige Zeichencodierung UTF-8 oder gar keine Zeichencodierung angibt.
LLAP 🖖
Also, laut meinem Hoster ist der Server auf die Zeichencodierung UTF-8 eingestellt.
Ich habe allerdings bemerkt, ich benutze ja den Notepad++ das die Kodier-Einstellungen auf UTF-8 eingestellt sind, habs gespeichert und nun gibt es neue Fehlermeldungen:
Es gibt zwei Möglichkeiten : rein UTF-8 und UTF-8 ohne BOM.... (was DAS wieder ist....)
Diese (verlinkte) Unterseite ist mit UTF-8 kodiert.
ächtZ
Grüsse der einsiedelnde
Hallo,
Also, laut meinem Hoster ist der Server auf die Zeichencodierung UTF-8 eingestellt.
vielleicht als Default, das mag ja sein. Wenn ich http://www.tassilo.sturm.serverma.de/work.php anfordere, erhalte ich aber vom Server die Auskunft:
Content-Type: text/html; charset=iso-8859-1
Wenn der Default in der Serverkonfiguration auf UTF-8 eingestellt ist, könnte es sein, dass du diesen Wert bewusst oder unbewusst überschreibst. Entweder mit einer AddDefaultCharset-Direktive in einer .htaccess, oder im PHP-Script.
Die tatsächlich verwendete Codierung ist aber UTF-8, und weil das Dokument mit einer BOM beginnt, erkennt der Browser die Codierung auch korrekt als UTF-8. Gibt er in Page Info auch so an.
Ich habe allerdings bemerkt, ich benutze ja den Notepad++ das die Kodier-Einstellungen auf UTF-8 eingestellt sind, habs gespeichert und nun gibt es neue Fehlermeldungen:
Hä?
Es gibt zwei Möglichkeiten : rein UTF-8 und UTF-8 ohne BOM.... (was DAS wieder ist....)
Eine BOM (Byte Order Mark) ist ein Steuerzeichen, das vom Editor am Dateianfang eingefügt wird und der verarbeitenden Software (z.B. dem Browser) die verwendete Codierung mitteilt. Die BOM hat Vorrang vor der oben erwähnten Info im HTTP-Header.
Hmm. Wenn der Validator von ISO-8859-1 ausgeht und dann auch noch Windows-1252 sieht, bekommt er anscheinend was anderes als mein Browser, wenn ich das Dokument direkt aufrufe ...
EDIT: Kann es sein, dass der Validator die BOM ignoriert und deshalb von ISO-8859-1 ausgeht? Und dann einige der Bytes, die UTF-8-Codes für Zeichen >0x80 bilden, für Windows-1252 hält? Dann läge in diesem Fall der Fehler nicht nur beim Autor, sondern auch beim Validator.
So long,
Martin
@@Der Martin
und weil das Dokument mit einer BOM beginnt, erkennt der Browser die Codierung auch korrekt als UTF-8.
„Der Browser“? Nein! IrgendEin von unbeugsamen Redmondern entwickelter Browser hört nicht auf, Widerstand zu leisten.
Jemand am Rand unterwegs und kann das mal evaluieren, ob das in Edge auch noch so ist?
Eine BOM (Byte Order Mark) ist ein Steuerzeichen, das vom Editor am Dateianfang eingefügt wird und der verarbeitenden Software (z.B. dem Browser) die verwendete Codierung mitteilt.
Sofern es sich um eine Unicode-Codierung handelt. Und das BOM teilt nicht die verwendete Codierung mit, sondern die Reihenfolge der Bytes – wie der Name byte order mark sagt. Also ob es sich bswp. bei UTF-16 um UTF-16BE oder UTF-16LE handelt.
Bei UTF-8 ist die Reihenfolge der Bytes festgelegt; ein BOM also nicht erforderlich.
EDIT: Kann es sein, dass der Validator die BOM ignoriert und deshalb von ISO-8859-1 ausgeht?
Sieht so aus. Und DER Validator tut das auch.
Und dann einige der Bytes, die UTF-8-Codes für Zeichen >0x80 bilden, für Windows-1252 hält?
Auch das.
Dann läge in diesem Fall der Fehler nicht nur beim Autor, sondern auch beim Validator.
Die Nichtbeachtung des BOM ist ein Bug. Fehlerhaftes ISO 8859-1 als Windows-1252 zu verarbeiten ist ein Feature.
LLAP 🖖
Hallo,
und weil das Dokument mit einer BOM beginnt, erkennt der Browser die Codierung auch korrekt als UTF-8.
„Der Browser“? Nein! IrgendEin von unbeugsamen Redmondern entwickelter Browser hört nicht auf, Widerstand zu leisten.
na toll, der schon wieder. War ja fast klar. ;-)
Früher hat er ja sogar gern mal den übermittelten Content-Type ignoriert und stattdessen anhand der ersten paar hundert Bytes Nutzdaten selbst geraten. Tun aktuelle Versionen das auch immer noch?
Eine BOM (Byte Order Mark) ist ein Steuerzeichen, das vom Editor am Dateianfang eingefügt wird und der verarbeitenden Software (z.B. dem Browser) die verwendete Codierung mitteilt.
Sofern es sich um eine Unicode-Codierung handelt.
Äh, ja richtig. Sie teilt einerseits die Tatsache mit, dass eine Unicode-Codierung verwendet wird, und noch dazu, welche und in welcher Variante.
Und das BOM
Das? Egal ob ich Byte Order Mark letztendlich mit "Marke" oder "Markierung" übersetze, es ist in beiden Fällen "die". Wovon gehst du aus?
teilt nicht die verwendete Codierung mit, sondern die Reihenfolge der Bytes
Auch die Codierung an sich, denn man kann daran auch UTF-8 von UTF-16 (und vermutlich auch von UTF-32) unterscheiden.
Bei UTF-8 ist die Reihenfolge der Bytes festgelegt; ein BOM also nicht erforderlich.
Richtig. Aber am Vorhandensein der magischen drei Bytes kann man UTF-8 dennoch erkennen.
EDIT: Kann es sein, dass der Validator die BOM ignoriert und deshalb von ISO-8859-1 ausgeht?
Sieht so aus. Und DER Validator tut das auch.
Das ist nicht schön. :-(
Dann läge in diesem Fall der Fehler nicht nur beim Autor, sondern auch beim Validator.
Die Nichtbeachtung des BOM ist ein Bug. Fehlerhaftes ISO 8859-1 als Windows-1252 zu verarbeiten ist ein Feature.
Ja. Aber UTF-8 mit oder ohne BOM zu servieren, dann aber im HTTP-Header ISO-8859-1 anzugeben, ist IMO auch ein Bug. Der des Autors, den ich hier meinte.
Ciao,
Martin
@@Der Martin
Das? Egal ob ich Byte Order Mark letztendlich mit "Marke" oder "Markierung" übersetze, es ist in beiden Fällen "die". Wovon gehst du aus?
Das Zeichen.
Auch die Codierung an sich, denn man kann daran auch UTF-8 von UTF-16 (und vermutlich auch von UTF-32) unterscheiden.
Bei big endian beginnen UTF-16 und UTF-32 mit xFE xFF. OK, bei UTF-32 folgt danach x00 x00. In UTF-16 wäre das U+0000, was in einem Dokument nicht vorkommen sollte.
LLAP 🖖
Tach,
Und das BOM
Das? Egal ob ich Byte Order Mark letztendlich mit "Marke" oder "Markierung" übersetze, es ist in beiden Fällen "die". Wovon gehst du aus?
es gibt keine festen Regeln für den Genus von Fremdwörtern und die Übersetzung ist nur eine davon ;-) Ich würde auch eher das BOM sagen.
mfg
Woodfighter
Hallo,
Und das BOM
Das? Egal ob ich Byte Order Mark letztendlich mit "Marke" oder "Markierung" übersetze, es ist in beiden Fällen "die". Wovon gehst du aus?
es gibt keine festen Regeln für den Genus von Fremdwörtern und die Übersetzung ist nur eine davon ;-)
aber doch eine naheliegende, oder nicht? Zumindest wenn sonst keine vergleichbaren Fälle vorliegen.
Außerdem ist es in diesem Fall besonders schwierig: Zum einen ist es ein fremdsprachlicher Begriff, und dann auch noch ein Akronym.
Ich würde auch eher das BOM sagen.
Meinem Sprachgefühl widerstrebt das. Ebenso, wenn die Formel1-Experten "der Speed" sagen.
Ciao,
Martin
@@Der Martin
Ich würde auch eher das BOM sagen.
Meinem Sprachgefühl widerstrebt das.
Im bereits verlinkten Artikel heißt es auch „das BOM“. Was beweist, dass ich recht habe. :-D
Zumindest gibt es beim BOM auch fürs weibliche Geschlecht eine nachvollziehbare Erklärung – im Gegensatz zu URL und API.
LLAP 🖖
Hi,
Im bereits verlinkten Artikel heißt es auch „das BOM“. Was beweist, dass ich recht habe. :-D
natürlich, aber es gibt häufig nicht nur ein "richtig".
Zumindest gibt es beim BOM auch fürs weibliche Geschlecht eine nachvollziehbare Erklärung – im Gegensatz zu URL und API.
Die Diskussion über URL hatten wir ja schon mehrfach, an meiner Überzeugung hat sich da auch nichts geändert. Und die API ist eigentlich klar, weil "die Schnittstelle", auch wenn sich als einzeln stehender Begriff das Interface etabliert hat. Oder welches Geschlecht würdest du für API zuordnen wollen? Männlich? Sächlich? Wenn ja, warum?
Ich verwende eigentlich schon immer die API und habe das auch schon oft so gelesen; das API ist gefühlt seltener, weckt bei mir aber weniger Abneigung als das BOM.
Ciao,
Martin
Hallo Gunnar Bittersmann,
Im bereits verlinkten Artikel heißt es auch „das BOM“. Was beweist, dass ich recht habe. :-D
Zumindest gibt es beim BOM auch fürs weibliche Geschlecht eine nachvollziehbare Erklärung – im Gegensatz zu URL und API.
Der Bom, eindeutig.
Bis demnächst
Matthias
Hallo Gunnar Bittersmann,
„Der Browser“? Nein! IrgendEin von unbeugsamen Redmondern entwickelter Browser hört nicht auf, Widerstand zu leisten.
Jemand am Rand unterwegs und kann das mal evaluieren, ob das in Edge auch noch so ist?
Gibts ein Testdokument, am besten gleich zwei zum Vergleichen?
Bis demnächst
Matthias
@@Matthias Apsel
Gibts ein Testdokument
Aktuell das von einsiedler.
BOM sagt UTF-8; HTTP sagt ISO 8859-1.
BOM sollte gewinnen und „Münster“ und „möchte“ sollten als UTF-8 decodiert richtig angezeigt werden.
LLAP 🖖
Hallo Gunnar Bittersmann,
Gibts ein Testdokument Aktuell das von einsiedler. BOM sagt UTF-8; HTTP sagt ISO 8859-1. BOM sollte gewinnen und „Münster“ und „möchte“ sollten als UTF-8 decodiert richtig angezeigt werden.
Derzeit sieht es im Edge unter Win 10 genau so aus. Und im IE 11 unter Win 7 ist es fehlerhaft.
PS: Deine Notificationen sind wohl ausgeschaltet?
Bis demnächst
Matthias
na SUPI,
und was mache ich nun?
Inwieweit liegt der Fehler (auch) bei mir?
So: <meta charset="utf-8"/> habe ich es angegeben.
Und nur bei der php-Unterseite ist der Fehler, aber ich habe weder ein .htaccess, noch im PHP-Script eine order (zum überschreiben) gegeben.
seufZ
der einsiedelnde
Hej einsiedler,
na SUPI,
und was mache ich nun?
ich habe weder ein .htaccess
Dann nimm doch einfach eine fertige (z. B. von der html5boilerplate...
Gruß,
MarcTRIX
@@einsiedler
und was mache ich nun?
Lesen, was ich dir bereits verlinkt hatte.
LLAP 🖖
Entschuldige das ich grad "auf dem Schlauch stehe", ich weiss jetzt nicht welchen link Du meinst!
@@einsiedler
Entschuldige das ich grad "auf dem Schlauch stehe", ich weiss jetzt nicht welchen link Du meinst!
„Sorge dafür, dass dein Server entweder auch die richtige Zeichencodierung UTF-8 oder gar keine Zeichencodierung angibt.“
LLAP 🖖
 Gunnar Bittersmann
Gunnar Bittersmann Der Martin
Der Martin Matthias Apsel
Matthias Apsel marctrix
marctrix