


Tester gesucht
pl
- perl
 nicht angemeldet
nicht angemeldetHallo,
hab einen neuen Serializer entwickelt, derzeit in Testphase für Sessiondateien. Wer Lust, Zeit und Interesse hat, möge mal den damit realisierten Login/Logout testen, siehe "Problematische Seite" Link. Also mal ein paarmal ein/ausloggen.
Es soll nicht umsonst sein, Algorithmus und Source lege ich offen, siehe untenstehend.
MfG
package FreezeHash;
# Recursive serialize for hash of hashes
# ALGORITHMUS
# Die Datenstruktur wird als Baum aufgefasst und rekursiv durchlaufen
# Dabei wird jeder Eintrag erfasst und bekommt eine eigene Entity-ID
# als fortlaufende Nummer. Im Ergebnis dessen entsteht eine lineare
# Struktur: ein einfacher Hash of Hashes nach dem Muster
# Entity/Attribute/Value kurz EAV
# In der linearisierten Struktur ist für jeden Knoten der parent
# als Attribut hinzugefügt und damit kann die Original-
# Datenstruktur wiederhergestellt werden.
use strict;
use warnings;
use IO::File;
use Fcntl qw(:flock);
use Carp;
use bytes;
#use Data::Dumper;
#$Data::Dumper::Sortkeys = 1;
sub new{
my $class = shift;
my %cfg = (
file => '', # full qualified
lock => 0, # atomar read+write
auto => 0, # auto write to file
@_);
return eval{
my $fh = IO::File->new;
$fh->open( $cfg{file}, O_CREAT|O_BINARY|O_RDWR) ||
croak "Error open file '$cfg{file}': $!";
if( $cfg{lock} ){
flock($fh, LOCK_EX) ||
carp "Your system does'nt support flock!";
}
bless{
lfdnr => 1, # root entity
EAV => {},
FH => $fh ,
CFG => \%cfg # for debug
}, $class;
};
}
# Linearisierung der geschachtelten Datenstruktur
sub freeze{
my $self = shift;
my $ds = shift;
my $parent = shift || $self->{lfdnr};
# Hash wird rekursiv durchlaufen und linearisiert
# Jeder Eintrag bekommt eine fortlaufende Nummer
foreach my $key( keys %$ds ){
if( ref $ds->{$key} eq 'HASH' ){
my $ent = $self->_lfdnr(1);
$self->{EAV}{$ent} = {
type => 'HASH',
att => $key,
parent => $parent,
ent => $ent
};
$self->freeze( $ds->{$key} );
}
else{
my $ent = $self->_lfdnr(1);
$self->{EAV}{$ent} = {
parent => $parent,
type => 'STRING',
att => $key,
val => $ds->{$key},
ent => $ent
};
}
}
# ab hier kann serialisiert werden
# serialisiert wird beim write()-Aufruf
}
# Datenstruktur wiederherstellen
sub thaw{
my $self = shift;
# aus Datei deserialisieren, Ergebnis ist
# eine linearisierte Datenstruktur
$self->_read;
# die ursprüngliche Datenstruktur wiederherstellen
$self->{RESTORED} = {};
# Knoten direkt unterhalb der Wurzel haben entity 1
foreach my $root( @{$self->{CHILDREN}{1}} ){
if( $self->{EAV}{$root}{type} eq 'STRING' ){
$self->{RESTORED}{$self->{EAV}{$root}{att}} = $self->{EAV}{$root}{val};
}
else{
$self->{RESTORED}{$self->{EAV}{$root}{att}} = {};
foreach my $child ( @{$self->{CHILDREN}{$root}} ){
$self->_restore($self->{RESTORED}{$self->{EAV}{$root}{att}}, $self->{EAV}{$child});
}
}
}
return $self->{RESTORED};
}
# Daten in das Handle serialisieren
sub write{
my $self = shift;
# STRING kann undef sein, hierzu wird ein byte vergeben 0|1
# zur Kennzeichnung undef oder String
$self->{FH}->seek(0,0);
$self->{FH}->truncate(0);
foreach my $ent( keys %{$self->{EAV}} ){
foreach my $att( keys %{$self->{EAV}{$ent}} ){
my $def = $self->{EAV}{$ent}{$att} ? 1 : 0;
my $val = $def ? $self->{EAV}{$ent}{$att} : '';
# pack with little endians
$self->{FH}->print(
pack('VVV', length $ent, length $att, length $val).$def.$ent.$att.$val
);
}
}
return 1;
}
sub DESTROY{
my $self = shift;
if( $self->{CFG}{auto} ){ $self->write }
$self->{FH}->close;
}
#################################### Private ##############################
# wird rekursiv aufgerufen, aus der linearen EAV Struktur
# das Original wiederherstellen
sub _restore{
my $self = shift;
my $href = shift; # aktueller stub
my $hunt = shift; # hash der angefügt werden soll
if( $hunt->{type} eq 'STRING' ){
$href->{$hunt->{att}} = $hunt->{val};
}
else{
# hier der rekursive Aufruf
$href->{$hunt->{att}} = {};
foreach my $child( @{$self->{CHILDREN}{$hunt->{ent}}} ){
$self->_restore($href->{$hunt->{att}}, $self->{EAV}{$child});
}
}
}
# Lese Dateihandle und deserialize
sub _read{
my $self = shift;
$self->{FH}->seek(0,0);
$self->{EAV} = {};
my %CHLD = (); # parent-children relation
while( read($self->{FH}, my $buffer, 12) ){
my($elen,$alen,$vlen) = unpack 'VVV', $buffer;
read($self->{FH}, my $def, 1);
read($self->{FH}, my $ent, $elen);
read($self->{FH}, my $att, $alen);
read($self->{FH}, my $val, $vlen);
# Korrektur wenn value = undef
$val = undef if $def eq '0' && $att eq 'val';
$self->{EAV}{$ent}{$att} = $val;
if( $att eq 'parent' ){
push @{$CHLD{$val}}, $ent;
}
}
$self->{CHILDREN} = \%CHLD;
}
# Laufende Nummer zur Verwaltung der eigenen Entities
sub _lfdnr{
my $self = shift;
my $countup = shift || 0;
return $countup ? ++$self->{lfdnr} : $self->{lfdnr};
}
1;#########################################################################
__END__
use strict;
use warnings;
use Data::Dumper;
$Data::Dumper::Sortkeys = 1;
# data struct
my $ds = {
name => 'boo',
nixdef => undef,
addr => {
addr_name => 'foo',
addr_vname => 'bar'
},
base => {
base_addr => {
base_addr_name => 'foo',
base_addr_vname => 'bar',
base_addr_undef => undef,
base_addr_hash => { base_addr_hash_name => 'otto' },
},
},
#env => \%ENV
};
my $fr = FreezeHash->new( file => 'freeze.bin' ) or die $@;
$fr->freeze( $ds );
$fr->write or die $@;
my $res = $fr->thaw;
print Dumper $res,$ds;
Hallo Rolf,
mir ist der Anwendungsfall nicht klar.
Für mich ist es nichts Besonderes, verschiedenen Usern unterschiedliche Inhalte unter gleicher URL anzubieten.
User A darf den Lagerbestand sehen, User B auch den Einkaufspreis. Aber das ist wohl nicht gemeint?
Gruß, Linuchs
Für mich ist es nichts Besonderes, verschiedenen Usern unterschiedliche Inhalte unter gleicher URL anzubieten.
Wie machst Du das?
Aber das ist wohl nicht gemeint?
Ursprünglich nicht aber wenn wir schon einmal dabei sind, erzähl mal bitte wie Du das machst.
MfG
... aber wenn wir schon einmal dabei sind, erzähl mal bitte wie Du das machst.
User mit Kennwort A loggt sich ein. Programm liest den User-Stammsatz, prüft, ob das Passwort stimmt und weiss, dass User A die Daten des Mandanten 1 mit der Berechtigungsstufe 9 (1..9) sehen darf. Stammsatz bekommt einen Timestamp, der nun von Programm zu Programm mit dem Kennwort weitergereicht wird.
Es gibt nur ein (Haupt)Programm: index.php - dem muss mitgeteilt werden, welches (Ziel)Programm zp aufzurufen ist (per include). Ebenso wird das Kennwort kw und das Timestamp ll (last-login) mitgegeben. Dann werden noch Parameter für das Zielprogramm angehängt:
http://example.com/?kw=A&ll=1493860611&zp=p101&adr_kz=1
index.php liest bei jedem einzelnen Aufruf den User-Stammsatz und prüft das last-login. Wenn es nicht (mehr) gültig ist, wird das Login-Programm included, ansonsten das gewünschte Zielprogramm.
Jeder Datenzugriff bezieht sich auf den für User A festgelegten Mandanten, in der DB owner_id genannt:
SELECT
...
FROM artikel
WHERE owner_id = $row_user['owner_id']
...
So hat also User A total andere Daten als User B, der Mandant 2 bearbeitet.
Das Zielprogramm kann nun noch Felder anzeigen, abhängig von der Berechtigung 9 (hoch) des Users A. User C möge auch Mandant 1 bearbeiten, aber nur die Berechtigung 4 (niedrig) haben.
Rest ist doch einfach, sinngemäß so:
echo $row_artikel['lagermenge'];
if ( $row_user['berechtigung'] > 5 ) echo $row_artikel['ek_preis'];
Das Konzept mit dem zentralen Programm index.php kann genutzt werden, um die URL extrem klein zu halten: http://remso.eu/?ORT=6817
Eine Dateiangabe fehlt, also wird Programm index.php genommen. Das checkt die mitgegebenen Parameter und weiss, dass für einen ORT das Zielprogramm p591b aufzurufen ist. Dieses wiederum wertet die ort_id 6817 aus und zeigt die Termine an.
Wenn ich nicht die Termine anzeigen, sondern den Orts-Stammsatz bearbeiten möchte, muss ich das Zielprogramm nennen: http://remso.eu/?zp=p152&kw=A&ll=1485935384&ORT=6817
Das Ganze ist ein Baukasten-System für Software-Kunden, an dem ich seit 1985 arbeite, damals noch mit Turbo-Pascal, in 2001 überarbeitet und übertragen nach PHP.
Linuchs
Das Ganze ist ein Baukasten-System für Software-Kunden, an dem ich seit 1985 arbeite, damals noch mit Turbo-Pascal, in 2001 überarbeitet und übertragen nach PHP.
Klasse! Ja, die Idee ist gut, danke für Deine ausführlichen Ausführungen.
VlG, Rolf
Hi,
aber unabhängig davon, ob das ganze über eine index.php läuft, funktioniert doch im Prinzop jedes Berechtigungssystem so.
Ich kann bei mir z.b. nicht nur Berechtigungsstufen (Admin, User, usw.) festlegen, sondern darüber hinaus auch für bestimmte Usernamen noch Berechtigungen festlegen.
Und das, selbstredend auch ohne, dass es über eine index.php läuft, sondern auch über ganz normale scriptnamen.php.
Beppo
aber unabhängig davon, ob das ganze über eine index.php läuft, funktioniert doch im Prinzop jedes Berechtigungssystem so.
Nein. Meins funktioniert komplett anders, nämlich nach dem Prinzip der Content-Negotiation die bereits unter der Konfiguration des gesamten Webauftritts ansetzt. Damit ist die ganze Policy komplett vom Code getrennt, meine Anwendungsklassen haben mit Berechtigungen gar nichts mehr zu tun.
MfG
aber unabhängig davon, ob das ganze über eine index.php läuft, funktioniert doch im Prinzop jedes Berechtigungssystem so.
Nein. Meins funktioniert komplett anders, nämlich nach dem Prinzip der Content-Negotiation die bereits unter der Konfiguration des gesamten Webauftritts ansetzt. Damit ist die ganze Policy komplett vom Code getrennt, meine Anwendungsklassen haben mit Berechtigungen gar nichts mehr zu tun.
MfG
Hi,
wenn dem so ist, bringt Dir auch Linuchs Idee nicht so viel. Letztlich läufts dann eben doch auf Berechtigungen hinaus, egal, auf welcher Ebene Du ansetzt. Korrigiere mich, wenn ich falsch liege, aber das, was Linuchs erklärt, ist genau das, was ich meine. Beppo
wenn dem so ist, bringt Dir auch Linuchs Idee nicht so viel.
Ja. Stell Dir vor, Du hast ein Framework und möchtest da einen WebAppliaction-Server (WAS) integrieren der mandantenfähig sein soll. Da ist es gar nicht möglich, die Berechtigungen erst in der Anwendung zu prüfen. Vielmehr wird für den WAS eine Gruppe admitted und die Mandanten sind Benutzer dieser Gruppe. So wie für alle anderen Inhalte und Anwendungen auch. Fertig.
Schönen Sonntag.
hab einen neuen Serializer entwickelt, derzeit in Testphase für Sessiondateien. Wer Lust, Zeit und Interesse hat, möge mal den damit realisierten Login/Logout testen
Habe Deinen Code gerade 1:1 kopiert und getestet, allerdings mit einem deutlich größeren Hash:
my $ds = {};
for (my $i = 0; $i < 10000; $i++) {
$ds->{'name' . rand(1)} = 'xyz' . rand(1);
$ds->{'foo' . rand(1)} = 'bar' . rand(1);
}
my $fr = FreezeHash->new( file => 'freeze.bin' ) or die $@;
$fr->freeze( $ds );
$fr->write or die $@;
Ergebnis auf meinem Testsystem: ca. 600ms Laufzeit, freeze.bin ist ca. 3000KB groß.
Gegenvergleich mit derselben Datenstruktur, aber mittles JSON umgesetzt:
use JSON ();
my $ds = {};
for (my $i = 0; $i < 10000; $i++) {
$ds->{'name' . rand(1)} = 'xyz' . rand(1);
$ds->{'foo' . rand(1)} = 'bar' . rand(1);
}
open (OUTFILE, '>:utf8', 'freeze.json');
print OUTFILE JSON->new()->encode($ds), "\n";
close OUTFILE;
Ergebnis auf meinem Testsystem: ca. 70ms Laufzeit, freeze.json ist ca. 900KB groß.
Fazit: Dein Serializer braucht beinahe 10x so lange wie JSON und erzeugt dabei ca. 3x so große Dateien. Wenn Du schon was proprietäres baust, sollte es sich zumindest auf irgendeine Weise lohnen?!
Hallo,
Wenn Du schon was proprietäres baust, sollte es sich zumindest auf irgendeine Weise lohnen?!
Manchmal ist der Lohn einfach der, dass mans selbst gebaut hat!
Gruß
Kalk
Manchmal ist der Lohn einfach der, dass mans selbst gebaut hat!
Totschlagargument. Spielverderber!
Danke für den Hinweis!
Wenn Du schon was proprietäres baust, sollte es sich zumindest auf irgendeine Weise lohnen?!
Mein Algorithmus ist binary safe, das ist JSON nicht.
MfG
Mein Algorithmus ist binary safe, das ist JSON nicht.
Das ist nativ in JSON nicht vorgesehen, stimmt. Ich bin bei Binärdaten in solchen Geschichten grundsätzlich eher skeptisch, aber wenn man es den braucht: Base64. Ja, das hat seinen eigenen Overhead.
Mein bisheriger Serializer für die Sessions ist Storable::freeze und Storable::thaw. Der Storable-Algorithmus ist in c implementiert und daher sehr performant. Für Sessiondateien die ohnehin nicht portable sein müssen, ist Storable der ideale Serializer und binsafe ist Storable auch.
Mit Storable erzeugte Binaries sind jedoch alles andere als kompatibel über unterschiedliche Plattformen und auch Perlversionen hinweg. Ein eigener Algorithmus ist da unumgänglich und so habe ich für EAV Datenstrukturen einen Algorithmus entwickelt den ich auch in c, Perl, PHP und JavaScript implementiert habe. D.h., damit erzeugte Dateien sind allesamt mit og. Programmier- bzw. Scriptsprachen lesbar.
EAV Structs sind linear aufgebaut und lassen sich auch in einer ganz normalen MySQL Tabelle einfrieren wobei die Daten sogar durchsuchbar sind. Damit lassen sich Data Access Layer realisieren wo nur noch die Anwendung über die Daten bestimmt und nur der DAL über den Speicherort.
Das sind die Vorteile eigener Serializer und wie wir sehen kommt da Einiges mehr zusammen als nur die Freude übers Selbstgemachte.
Die Idee hinter dem hier vorgestellten Serializer ist die Linearisierung geschachtelter Datenstrukturen. Wenn ich das in c implementiere wird das genauso schnell wie JSON, davon bin ich überzeugt, auch wenn die Sequenzen länger sind.
MfG
[...] Ein eigener Algorithmus ist da unumgänglich
Why? Das einzig schlüssige Argument bislang von Dir lautet: binsafe. Base64 existiert.
Die Idee hinter dem hier vorgestellten Serializer ist die Linearisierung geschachtelter Datenstrukturen.
JSON
Wenn ich das in c implementiere wird das genauso schnell wie JSON, davon bin ich überzeugt, auch wenn die Sequenzen länger sind.
Traue ich Dir absolut zu! Nur: warum nimmst Du nicht einfach JSON?
Das einzig schlüssige Argument bislang von Dir lautet: binsafe.
Nein es ist nicht das einzige Argument. Du hast die restlichen Argumente nur nicht verstanden!
warum nimmst Du nicht einfach JSON?
Weil mein Algorithmus performanter ist, ganz einfach. JSON arbeitet zeichenorientiert, mein Serializer hingegen arbeitet auf Byteebene mit Offset. Das ist grundsätzlich performanter als Algorithmen mit Charactersemantic. Das habe ich hier aber schon mehrfach erklärt, Du bist doch lange genug dabei oder?
Im Übrigen: Base64 hat mit Serializer-Algorithmen gar nichts zu tun. Aber soweit wollte ich nun auch wieder nicht ausholen.
MfG
Das einzig schlüssige Argument bislang von Dir lautet: binsafe. Nein es ist nicht das einzige Argument. Du hast die restlichen Argumente nur nicht verstanden!
Ah, ok. Danke für die schlüssige Erklärung!
warum nimmst Du nicht einfach JSON? Weil mein Algorithmus performanter ist, ganz einfach.
Ich habe den Beweis für das Gegenteil geliefert. Du nicht. Wird auch nicht kommen, wie immer.
Ich habe den Beweis für das Gegenteil geliefert.
Nein hast Du nicht. Ich habe es nämlich selbst kontrolliert und dabei festgestellt, dass es genau umgekehrt ist als das was Du da behauptest!
Hinter Deiner Falschmeldung stecken niedrige Beweggründe die eines Entwicklers nicht würdig sind. Ich finde es nur allzu traurig dass sowas noch von diesem Forum unterstützt wird.
MfG
Ich habe den Beweis für das Gegenteil geliefert.
Nein hast Du nicht.
Ich denke wohl. Allerdings hast Du insofern Recht, dass während meiner Messung kein öffentlich bestellter Gutachter zugegen war und insofern hier jetzt Aussage gegen Aussage steht. Dein/mein Code dazu steht hier im Thread zur Verfügung und jeder, wenn er denn möchte, kann seine eigene Messung vornehmen.
Ich habe es nämlich selbst kontrolliert und dabei festgestellt, dass es genau umgekehrt ist als das was Du da behauptest!
Glaube Dir jetzt einfach mal aus tiefstem, naivem Vertrauen heraus. Dann wird wohl Deine Perl-Installation kaputt sein.
Ich habe den Beweis für das Gegenteil geliefert.
Nein hast Du nicht. Ich habe es nämlich selbst kontrolliert und dabei festgestellt, dass es genau umgekehrt ist als das was Du da behauptest!
Mach mal einen Screenshot, bitte.
Hinter Deiner Falschmeldung stecken niedrige Beweggründe die eines Entwicklers nicht würdig sind.
Du bist am Zug, meine Messungen zu widerlegen. Bislang lesen wir von Dir nur Behauptungen, das musst Du wohl oder übel eingestehen.
Dir ist schon bewusst, dass Du dir in bereits in einem Post selber widersprichst?
Ein eigener Algorithmus ist da unumgänglich und so habe ich für EAV Datenstrukturen einen Algorithmus entwickelt den ich auch in c, Perl, PHP und JavaScript implementiert habe.
Du hast das Dingen also auch bereits in C geschrieben. Klare Aussage.
Wenn ich das in c implementiere wird das genauso schnell wie JSON, davon bin ich überzeugt, auch wenn die Sequenzen länger sind.
"wenn Du das in C implementierst." Was denn nun?
Dein heute morgen hier propagierter Vergleich ist ohne Belang.
Mein Vergleich: JSON braucht doppelt so lange wie mein hier vorgestellter Algorithmus. Das habe ich soeben auf meinem System festgestellt und habe auch nichts anderes erwartet.
Ich danke Dir aber trotzdem für Dein Interesse. MfG
Dein heute morgen hier propagierter Vergleich ist ohne Belang.
Nun ja, wenn Du meinst. Zumindest ist er mess- und nachvollviehbar.
Mein Vergleich: JSON braucht doppelt so lange wie mein hier vorgestellter Algorithmus. Das habe ich soeben auf meinem System festgestellt und habe auch nichts anderes erwartet.
Glaube ich Dir sogar! Vielleicht... Aber es ist leider nicht nachvollziehbar.
Ich danke Dir aber trotzdem für Dein Interesse. MfG
Klar! Gerne!
Netter Versuch. Aber ich lasse mich von Dir nicht verunsichern. Das haben schon ganz andere Leute versucht. Weißt Du, ein Entwickler zeichnet sich durch 3 Dinge aus:
Sie also Punkt 3. Aber wahrscheinlich bist Du kein Entwickler. MfG
Netter Versuch. Aber ich lasse mich von Dir nicht verunsichern.
Das war auch nie mein Ziel, Du siehst das persönlich, das ist Dein Hauptproblem.
Weißt Du, ein Entwickler zeichnet sich durch 3 Dinge aus:
- Pioniergeist
- Kreativität
- Beharrlichkeit
Ich finde diese Auflistung nicht besonders zielführend. Wenn, dann fehlt mir da aber mindestens noch "Punkt 4": Objektivität.
Sie also Punkt 3. Aber wahrscheinlich bist Du kein Entwickler.
Mag sein, das sollen andere beurteilen. Zum Beispiel Du ;-)
Weißt Du, ein Entwickler zeichnet sich durch 3 Dinge aus:
- Pioniergeist
- Kreativität
- Beharrlichkeit
Insbesondere:
„Der kompetente Kritiknehmer ist in der Lage, an ihn geäußerte Kritik konstruktiv zu verarbeiten. Da er den kreativen Konflikt nicht scheut, setzt er sich mit Kritik so auseinander, dass er einerseits die Kritik aus einer anderen Perspektive heraus akzeptiert, sich selbst also in Frage stellen kann, um gegebenenfalls das eigene Verhalten neu anzupassen und zu verbessern. Der kompetente Kritiknehmer prüft also Kritik anderer und erkennt gegebenenfalls seine eigenen Mängel in ihr wieder, um diese dann aufzuarbeiten. Zugleich legt er gegenüber der Kritik anderer Ernsthaftigkeit an den Tag. Er ist außerdem in der Lage, problematische Spannungen mit humorvoller Einstellung zu beantworten und so zu entschärfen. Andererseits ist dieser Typ nicht so eingestellt, dass er mit humorvoller Attitüde produktive kritische Situationen nivelliert. Der kompetente Kritiknehmer reflektiert seine kritischen Seiten und erkennt, dass Kritik zur Entwicklung seiner persönlichen Fähigkeiten beitragen kann.“
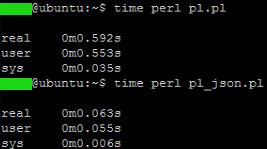
Ergänzend zum vorigen Post, der den fraglichen Code beinhaltet, anbei noch ein Screenshot meiner Messung.
Habe Deinen Code gerade 1:1 kopiert und getestet, allerdings mit einem deutlich größeren Hash: Ergebnis auf meinem Testsystem: ca. 600ms Laufzeit
"pl.pl" aus dem anhängendem Screenshot
Gegenvergleich mit derselben Datenstruktur, aber mittles JSON umgesetzt: Ergebnis auf meinem Testsystem: ca. 70ms Laufzeit
"pl_json.pl" aus dem anhängendem Screenshot
Wenn schon dann richtig:
use strict;
use warnings;
use Benchmark qw(cmpthese);
use JSON;
use IO::File;
# data struct
my $ds = {
name => 'boo',
nixdef => undef,
addr => {
addr_name => 'foo',
addr_vname => 'bar'
},
base => {
base_addr => {
base_addr_name => 'foo',
base_addr_vname => 'bar',
base_addr_undef => undef,
base_addr_hash => { base_addr_hash_name => 'otto' },
},
},
#env => \%ENV
};
my $freezer = sub{
my $fr = FreezeHash->new( file => 'd:/tmp/freeze.bin' ) or die $@;
$fr->freeze( $ds );
$fr->write;
my $res = $fr->thaw;
};
my $json = sub{
my $js = JSON->new;
my $FH = IO::File->new;
$FH->open("d:/tmp/json.asc", O_CREAT|O_RDWR) or die $!;
my $s = $js->encode($ds);
$FH->truncate(0);
$FH->seek(0,0);
$FH->print($s);
$FH->seek(0,0);
read($FH, my $content, -s $FH);
my $res = $js->decode( $content );
};
cmpthese(1000, {
'freezer' => $freezer,
'json' => $json
});
Rate freezer json
freezer 577/s -- -2%
json 587/s 2% --
Das ergibt quasi einen Gleichstand aber in keinster Weise das was Du hier versuchst der Welt beizubringen: Dass mein Algorithmus 10x langsamer sein soll ist eine glatte Lüge!
Wobei hierzu aber auch anzumerken ist, dass mit meinem Algorithmus die Datenstrukur tatsächlich zweimal durchlaufen wird, einmal beim Linearisieren und ein zweites Mal beim eigentlichen Serialisieren. Das Benchmark Modul ist jedoch nicht das allein entscheidende Kriterium, entscheidend ist das Verhalten auf dem produktiven System und das hat infolge meines neuen Serializer einen kleinen aber deutlichen Performanceschub bekommen -- gegenüber Storable::freeze+thaw und das obwohl Letzerer in c implementiert ist.
Im Übrigen ist JSON für meine Zwecke völlig indiskutabel. MfG
PS: Wenn ich %ENV mit reinnehme siehts so aus:
Rate json freezer
json 108/s -- -43%
freezer 189/s 75% --
Also ist mein Serializer doppelt so schnell aber das schrieb ich ja gestern bereits.
Wobei hierzu aber auch anzumerken ist, dass mit meinem Algorithmus die Datenstrukur tatsächlich zweimal durchlaufen wird, einmal beim Linearisieren und ein zweites Mal beim eigentlichen Serialisieren.
Wer hier ein bischen Pionierarbeit leisten möchte: Es gibt Möglichkeiten, auf den zweiten Durchlauf zu verzichten. Z.B. innerhalb der freeze() Methode, immer dann, wenn ein Tupel Entity/Attribute/Value erzeugt wurde, kann dieser sofort in das FileHandle geschrieben werden. Die Methode write() wird dann nicht mehr gebraucht und kann komplett entfallen.
Über eine diesbezügliche Diskussion hätte ich mich richtig gefreut! MfG
Wenn schon dann richtig: [...]
Nun, ich bin da ob Deiner Definition von "richtig" nicht ganz sicher. Der von Dir gepostete Code ist in sich nicht komplett, also musste ich, um es auf diese Art zu testen, noch Dein "package FreezeHash;" hinzufügen, dann konnte ich den Test starten. Da ich unter Linux kein Laufwerk "d:" habe, musste ich allerdings noch die Pfade anpassen, dann lief es durch. Allerdings wird eine Warnung ausgegeben: "(warning: too few iterations for a reliable count)". Dennoch werden Ergebnisse ausgegen, die sich aber deutlich von Deinen unterscheiden.
Erster Versuch, analog Deinem Code, ohne "%ENV":
Rate freezer json
freezer 2439/s -- -66%
json 7143/s 193% --
JSON ist hier ca. doppelt so schnell wie Deine Implementation.
Zweiter Versuch, analog Deinem Code, mit "%ENV":
Rate freezer json
freezer 1099/s -- -84%
json 6667/s 507% --
JSON ist hier ca. 5x so schnell wie Deine Implementation. Je größer die Datenstruktur, umso mehr scheint der Unterschied ins Gewicht zu fallen.
Glaube Dir allerdings, dass Deine Messung auf Deinem Testsystem so ausgefallen ist, wie Du schreibst. Deine Perl-Installation unter Deinem Windows wird für JSON vermutlich auf reinen Perl-Code zurückfallen, weil JSON:XS (das C-Kompilat) dort nicht verfügbar ist. Das könnte den Unterschied erklären.
Im Übrigen ist JSON für meine Zwecke völlig indiskutabel.
Wenn das so ist, dann ist das so! Für uns nachvollziehbar ist es allerdings nicht.
JSON vermutlich auf reinen Perl-Code zurückfallen, weil JSON:XS (das C-Kompilat) dort nicht verfügbar ist. Das könnte den Unterschied erklären.
Also wenn Du schon vergleichst dann richtig. Und "richtig" heißt dass der Algorithmus verglichen wird, d.h. beide Algorithmen sind in pure Perl.
Aber das habe ich Dir bereits mehrfach erklärt und auch warum JSON grundsätzlich langsamer ist als ein low-Level Algorithmus.
Im Übrigen habe ich meinen Algorithmus weiter optimiert, er ist jetzt 3x performanter als JSON. Was auch darauf zurückzuführen ist, das mein Algorithmus nun auch beim Linearisieren blockweise in das Handle schreibt. Somit entfällt ein zweiter Durchgang durch die linearisierte Datenstruktur, Linearisieren und Serialisieren ist nun ein Aufwasch. Stichwort: Streamfähigkeit.
Und da sind sie wieder diese 3 Dinge
was einen Programmierer auszeichnet. In meinen 15 Jahren als Schichtleiter war das übigens auch nicht anders.
MfG
Hi,
die Testphase ist nun im Wesentlichen abgeschlossen. Der neue Serializer bewährt sich hervorragend gegenüber meiner bisherigen Lösung mit Storable::freeze, insbesondere in Sachen Performanze. Den Data Access Layer hab ich komplett ausgetauscht und bei der Gelegenheit den Cleanup so geändert dass nicht mehr automatisch gespeichert wird sondern nur noch dann, wenn tatsächlich Daten für die Session anfallen (beispielsweise bei einem Login). Ansonsten haben die Sessiondateien eine Länge von 0 und gelöscht wird automatisch nach 24 Stunden.
Und so ganz nebenbei hat sich noch ein anderes Problem in Luft aufgelöst, was ich im Nachhinein nur auf einen Bug in Storable::freeze zurückführen konnte weil es bei gleichem SessionManagement mit einem anderen Serializer nunmehr nicht mehr auftritt, Schwamm drüber 😉
Ausschlaggebend ist immer der produktive Server, bei mehr als tausend Requests die täglich über das Framework laufen muss schon alles stimmen. MfG
 Orlok
Orlok