


mysql: Designfrage
Pit
- mysql
- programmiertechnik
 nicht angemeldet
nicht angemeldetHallo Forum,
ich überlege gerade, wie ich 2 Dinge möglichst effizient lösen kann (es geht um einen Kalender, der Termine erfassen soll).
Wiederholungen von Terminen. Es wäre einfach, wenn ich wüßte, dass ein Termin periodisch wiederholt wird bis zu einem Datum X. Das entspricht aber nicht immer (oder nur selten) der Praxis. Man macht dort nämlich einen Termin, gibt ihm eine periodische Wiederholung und weiß noch nicht, bis wann das so sein wird. Also denke ich mir, dass ich die vorhandenen Termine beim Abrufen des Kalenders erst erzeugen darf. (Ansonsten müßte ich ja auf Verdacht n Termine anlegen und könnte immer noch nicht sicher sein, dass ein User sich nicht einen Kalenderzeitraum anschauen möchte, der vor meinen auf verdacht angelegten n Terminen ist) Bedeutet aber im Umkehrschluss, dass ich bei jedem Erzeugen der Kalenderansicht alle(!) Termine durchgehen muß, die es jemals gab, um nach event. Wiederholungen zu suchen. Frage: Wie geht man designtechnisch sowas an?
Termine können Datumszuweisungen sein (01.01.2017). Will ich nun die erste Kalenderwoche anzeigen, kann ich im WHERE-Teil einfach ein WHERE Termin BETWEEN nutzen. Termine können aber auch Terminzeiträume sein (29.01.2017 - 08.02.2017). Will ich nun die ersten 10 Kalenderwochen 2017 anzeigen, wie gestaltet sich dann meine Query bezogen auf den WHERE Teil (s.o.)
Gruß, Pit
Hello,
grundsätzlich würde ich da die Methode "Papier und Buntstifte" an die erste Stelle setzen. Erst einmal genauestens alle Sichten, die in Frage kommen, aufmalen.
Erst dann kann man die Regeln und die Logik dafür entwickeln und anschließend das Datenmodell für die Datenbank daraus erzeugen.
Du scheinst umgekehrt vorgehen zu wollen. Das ist aber mMn nicht sinnvoll.
Liebe Grüße
Tom S.
Hallo TS,
Du scheinst umgekehrt vorgehen zu wollen. Das ist aber mMn nicht sinnvoll.
Das scheint nur so.
Pit
Tach!
- Wiederholungen von Terminen. Es wäre einfach, wenn ich wüßte, dass ein Termin periodisch wiederholt wird bis zu einem Datum X. Das entspricht aber nicht immer (oder nur selten) der Praxis. Man macht dort nämlich einen Termin, gibt ihm eine periodische Wiederholung und weiß noch nicht, bis wann das so sein wird. Also denke ich mir, dass ich die vorhandenen Termine beim Abrufen des Kalenders erst erzeugen darf. (Ansonsten müßte ich ja auf Verdacht n Termine anlegen und könnte immer noch nicht sicher sein, dass ein User sich nicht einen Kalenderzeitraum anschauen möchte, der vor meinen auf verdacht angelegten n Terminen ist)
Termine der Vergangenheit, die gar nicht stattgefunden haben, müssen auch nicht in den Kalender. Was ist das Problem, das du da genau siehst und das ich nicht erkenne?
Prinzipiell hast du die beiden Möglichkeiten, die du schon erkannt hast. Regel speichern und beim Abruf anwenden oder die Regel beim Erzeugen anwenden und konkrete Termine draus machen. Es wird nur dann eventuell schwierig, wenn die Regel gelöscht wird dass du dann alle dazugehörigen Termine, zumindest im Bereich der Zukunft, findest. Es gäbe da auch noch die Mischform, dass die Termine per Regel berechnet und angezeigt werden, aber bei konkreten Zusatzdaten die Termine fest in der Datenbank stehen. Dann musst du aber auch sehen, dass die Regel keinen zweiten Termin erzeugt.
Ich kann es nicht beurteilen, was in deinem Anwendungsfall sinnvoll(er) ist.
Bedeutet aber im Umkehrschluss, dass ich bei jedem Erzeugen der Kalenderansicht alle(!) Termine durchgehen muß, die es jemals gab, um nach event. Wiederholungen zu suchen.
Keine Ahnung. Vielleicht musst du da zwischen Vorschau (regelbasiert berechnete Anzeige) und tatsächlich stattgefundenhabenden Terminen (physischer Datensatz) einen Kompromiss finden.
- Termine können Datumszuweisungen sein (01.01.2017). Will ich nun die erste Kalenderwoche anzeigen, kann ich im WHERE-Teil einfach ein WHERE Termin BETWEEN nutzen. Termine können aber auch Terminzeiträume sein (29.01.2017 - 08.02.2017). Will ich nun die ersten 10 Kalenderwochen 2017 anzeigen, wie gestaltet sich dann meine Query bezogen auf den WHERE Teil (s.o.)
Ist die konkrete Frage, wie man sich überschneidende Zeiträume findet?
Abfragezeitraum |------------|
Terminzeitraum |-------|
Dann kannst du schauen, ob Start oder Ende im Abfragezeitraum liegen (logisches Oder, nicht das Exclusiv-Oder der natürlichen Sprache).
dedlfix.
Hi dedlfix,
Termine der Vergangenheit, die gar nicht stattgefunden haben, müssen auch nicht in den Kalender. Was ist das Problem, das du da genau siehst und das ich nicht erkenne?
Es ging nicht um Termine der Vergangenheit. Aber dieses Problem ist nun auch zugleich obsolet, weil Eure (Deine und Rolfs) Post mich auf einen besseren Weg geführt haben. (komme ich später drauf zurück)
Prinzipiell hast du die beiden Möglichkeiten, die du schon erkannt hast. Regel speichern und beim Abruf anwenden oder die Regel beim Erzeugen anwenden und konkrete Termine draus machen.
Hier ist er schon, der bessere Weg: Termine und Regel getrennt modellieren. Und durch Rolfs Post noch erweitert: Termine, Regel und Zeiträume getrennt modellieren.
Ist die konkrete Frage, wie man sich überschneidende Zeiträume findet?
Abfragezeitraum |------------| Terminzeitraum |-------|Dann kannst du schauen, ob Start oder Ende im Abfragezeitraum liegen (logisches Oder, nicht das Exclusiv-Oder der natürlichen Sprache).
Kannst Du mir das nochmal genauer erklären?
Pit
Tach!
Ist die konkrete Frage, wie man sich überschneidende Zeiträume findet?
Abfragezeitraum |------------| Terminzeitraum |-------|Dann kannst du schauen, ob Start oder Ende im Abfragezeitraum liegen (logisches Oder, nicht das Exclusiv-Oder der natürlichen Sprache).
Kannst Du mir das nochmal genauer erklären?
WHERE (Termin-Start BETWEEN Abfragezeitraum-Start AND Abfragezeitraum-Ende) OR
(Termin-Ende BETWEEN Abfragezeitraum-Start AND Abfragezeitraum-Ende)
dedlfix.
Hi dedlfix,
WHERE (Termin-Start BETWEEN Abfragezeitraum-Start AND Abfragezeitraum-Ende) OR (Termin-Ende BETWEEN Abfragezeitraum-Start AND Abfragezeitraum-Ende)
Danke.
Pit
Hi dedlfix,
Ist die konkrete Frage, wie man sich überschneidende Zeiträume findet?
Im Prinzip schon, aber dann doch etwas anders, als Du dachtest.
Ich versuchs mal zu erklären:
Datum: (1.7.) 2.7. 3.7. 4.7. 5.7. 6.7. (7.7.)(8.7.)
---------------------------------------------------------------------
Abfragezeitraum: |-----|-----|-----|-----|-----|
User 1 |-----| |-----|
User 2 |-----|-----|-----|
User 3 |-----|-----|-----|
User 4 |-----|-----|-----|-----|-----|-----|-----|-----|
soll als Ergebnis meiner Abfrage haben:
User 1: −
User 2: 4.7., 5.7., 6.7.
User 3: 6.7.
User 4: 2.7., 3.7., 4.7., 5.7., 6.7.
Und hier weiß ich nicht, wie ich das abfrage.
Pit
Tach!
Und hier weiß ich nicht, wie ich das abfrage.
Du kannst aus einer Datenbank mit einfacher Abfrage (also ohne zusätzliche Programmierlogik) immer nur das herausholen, was drinsteht. Wenn du nur einen Zeitraum als "A bis E" definierst und demzufolge nur A und E ohne B, C und D gespeichert hast, kannst du B, C und D nicht als einzelne Werte in der Ausgabe haben.
In der vorhergehenden Antwort habe ich noch den Fall übersehen, dass der Terminzeitraum vor dem Abfragezeitraum beginnt und danach endet. Das müsste noch ergänzt werden.
Es bleibt aber, dass du diese Abfrage prinzipiell verwenden kannst, um Einträge zu finden, die mindestens teilweise im Abfragezeitraum liegen. Die Ergebnismenge besteht also aus diesen Datensätzen, die nur jeweils die Werte A und B enthalten. Den Rest müsste dann das abfragende Programm ermitteln. In dem würde ich über den Abfragezeitraum iterieren, beispielsweise mit PHPs DatePeriod-Klasse. Zu jedem dieser Tage müsste nun geprüft werden, ob A kleiner/gleich und B größer/gleich ist, um zu ermitteln, ob er für die Ausgabe relevant ist.
dedlfix.
Hi dedlfix,
Du kannst aus einer Datenbank mit einfacher Abfrage (also ohne zusätzliche Programmierlogik) immer nur das herausholen, was drinsteht.
Klar. Aber SQL hat ja eine Unmenge an Programmierlogig bereits integriert.
In der vorhergehenden Antwort habe ich noch den Fall übersehen, dass der Terminzeitraum vor dem Abfragezeitraum beginnt und danach endet. Das müsste noch ergänzt werden.
Hatte ich geahnt, daher mein User 4. 😉 Kannst Du mir sagen, wie ich das ergänzen muß?
Es bleibt aber, dass du diese Abfrage prinzipiell verwenden kannst, um Einträge zu finden, die mindestens teilweise im Abfragezeitraum liegen. Die Ergebnismenge besteht also aus diesen Datensätzen, die nur jeweils die Werte A und B enthalten. Den Rest müsste dann das abfragende Programm ermitteln. In dem würde ich über den Abfragezeitraum iterieren, beispielsweise mit PHPs DatePeriod-Klasse. Zu jedem dieser Tage müsste nun geprüft werden, ob A kleiner/gleich und B größer/gleich ist, um zu ermitteln, ob er für die Ausgabe relevant ist.
Ich verstehe das nicht. ich verstehe es soweit, dass meine Ergebnismenge größer ist und über php dann auf die korrekte menge begrenzt wird. Mal eine Frage: Könnte das nicht dann sogar performanter sein, jedes "Tabellenfeld" selber abzufragen (ggf. über prepared Statement)? Unkomplizierter scheint mir das auf jeden Fall zu sein.
Pit
Tach!
Du kannst aus einer Datenbank mit einfacher Abfrage (also ohne zusätzliche Programmierlogik) immer nur das herausholen, was drinsteht.
Klar. Aber SQL hat ja eine Unmenge an Programmierlogig bereits integriert.
Ja, aber dazu müsstest du dich mit Stored Procedures befassen. Das ist sozusagen wie das Lernen einer Programmiersprache. Und dann kannst du dir ein Programm ausdenken, das das gewünschte Ergebnis bringt. Aber im Prinzip ist es egal, ob du das in einer Stored Procedure oder anderenorts (z.B. PHP) machst. Es ist jedenfalls deutlich aufwendiger als mal eben ein SQL-Statement aus dem Ärmel zu schütteln.
In der vorhergehenden Antwort habe ich noch den Fall übersehen, dass der Terminzeitraum vor dem Abfragezeitraum beginnt und danach endet. Das müsste noch ergänzt werden.
Hatte ich geahnt, daher mein User 4. 😉 Kannst Du mir sagen, wie ich das ergänzen muß?
Logik. Formuliere die Logik in normalen Worten aber exakt, dann hast du schon den Großteil, den du für das Formulieren des Codes brauchst. Ergänzen geht jedenfalls mit OR (die neue logik) zur vorhandenen Bedingung
Es bleibt aber, dass du diese Abfrage prinzipiell verwenden kannst, um Einträge zu finden, die mindestens teilweise im Abfragezeitraum liegen. Die Ergebnismenge besteht also aus diesen Datensätzen, die nur jeweils die Werte A und B enthalten. Den Rest müsste dann das abfragende Programm ermitteln. In dem würde ich über den Abfragezeitraum iterieren, beispielsweise mit PHPs DatePeriod-Klasse. Zu jedem dieser Tage müsste nun geprüft werden, ob A kleiner/gleich und B größer/gleich ist, um zu ermitteln, ob er für die Ausgabe relevant ist.
Ich verstehe das nicht. ich verstehe es soweit, dass meine Ergebnismenge größer ist und über php dann auf die korrekte menge begrenzt wird.
Deine Ergebnismenge ist vielmehr kleiner im Sinne der Aufgabenstellung, aber genau richtig, um die fehlenden Daten zu erzeugen.
Du hast deinen Abfragezeitraum und eine Menge Datensätze, die jeweils einen anderen Zeitraum beschreiben, der den Abfragezeitraum berührt. Und nun musst du aus diesen beiden Informationen jeweils die konkreten Tage ermitteln, die in beiden Zeiträumen liegen.
Mal eine Frage: Könnte das nicht dann sogar performanter sein, jedes "Tabellenfeld" selber abzufragen (ggf. über prepared Statement)? Unkomplizierter scheint mir das auf jeden Fall zu sein.
Unkompliziert kann sein, aber performant ist das nicht bei steigender Anzahl der Daten. Es ist eine Abwägungsfrage, und es wird den Bereich geben, ab dem eine solche Vorgehensweise anfängt, auffallend Zeit zu verbrauchen. Bei wenigen Datensätzen wirst du nichts merken, vielleicht auch noch nicht bei wenigen hundert oder tausend oder wie auch immer. Aber bedenke, dass du pro Datensatz und pro Tag des Abfragezeitraums eine Query absenden must. Das läppert sich recht schnell zusammen.
dedlfix.
Hi dedlfix,
Klar. Aber SQL hat ja eine Unmenge an Programmierlogig bereits integriert.
Ja, aber dazu müsstest du dich mit Stored Procedures befassen.
Ich meinte eigentlich noch simpler. Auch jede ("if-when-usw".) Abfrage ist ja schon Programmierlogig. (wenn auch in diesem Fall vielleicht nicht anwendbar).
Das ist sozusagen wie das Lernen einer Programmiersprache. Und dann kannst du dir ein Programm ausdenken, das das gewünschte Ergebnis bringt. Aber im Prinzip ist es egal, ob du das in einer Stored Procedure oder anderenorts (z.B. PHP) machst. Es ist jedenfalls deutlich aufwendiger als mal eben ein SQL-Statement aus dem Ärmel zu schütteln.
Ok.
Unkompliziert kann sein, aber performant ist das nicht bei steigender Anzahl der Daten. Es ist eine Abwägungsfrage, und es wird den Bereich geben, ab dem eine solche Vorgehensweise anfängt, auffallend Zeit zu verbrauchen. Bei wenigen Datensätzen wirst du nichts merken, vielleicht auch noch nicht bei wenigen hundert oder tausend oder wie auch immer. Aber bedenke, dass du pro Datensatz und pro Tag des Abfragezeitraums eine Query absenden must. Das läppert sich recht schnell zusammen.
Warum soll das bei zunehmenden Daten signifikant unperformanter sein? Solange der Abfragezeitraum z.b. auf 4 Wochen begrent ist, werden immer 28 Abfragen abgefeuert (natürlich auszuwählen aus einer steigenden Anzahl der Datenmenge). Und in der Ergebnismenge finden sich jeweils die Daten für alle User dieses Tages. Oder was meinst du genau?
Pit
Tach!
Klar. Aber SQL hat ja eine Unmenge an Programmierlogig bereits integriert.
Ja, aber dazu müsstest du dich mit Stored Procedures befassen.
Ich meinte eigentlich noch simpler. Auch jede ("if-when-usw".) Abfrage ist ja schon Programmierlogig. (wenn auch in diesem Fall vielleicht nicht anwendbar).
Im SELECT ist nur Abfragelogik anwendbar. Damit kann man keine Programme schreiben, die nicht vorhandene aber berechenbare Daten als Ergebnisdatensätze hinzufügen.
Unkompliziert kann sein, aber performant ist das nicht bei steigender Anzahl der Daten. Es ist eine Abwägungsfrage, und es wird den Bereich geben, ab dem eine solche Vorgehensweise anfängt, auffallend Zeit zu verbrauchen. Bei wenigen Datensätzen wirst du nichts merken, vielleicht auch noch nicht bei wenigen hundert oder tausend oder wie auch immer. Aber bedenke, dass du pro Datensatz und pro Tag des Abfragezeitraums eine Query absenden must. Das läppert sich recht schnell zusammen.
Warum soll das bei zunehmenden Daten signifikant unperformanter sein? Solange der Abfragezeitraum z.b. auf 4 Wochen begrent ist, werden immer 28 Abfragen abgefeuert (natürlich auszuwählen aus einer steigenden Anzahl der Datenmenge).
28 Abfragen für jede Zeile der Datenbank, eventuell vorgefiltern mit der bereits fast fertigen Query. 28 mal X Kommunikation mit dem DBMS. Das ist nicht wenig.
Und in der Ergebnismenge finden sich jeweils die Daten für alle User dieses Tages. Oder was meinst du genau?
Ach, so herum meinst du das. Ja, das geht natürlich auch, das braucht dann "nur" 28 Abfragen und nicht 28 mal X. Das beschränkt die Anzahl doch mehr, also ich dacht. 28 ist aber trotzdem schon ganz ordentlich. Besonders wenn Netzwerk dazwischen liegt und das DBMS nicht auf derselben Maschine läuft.
dedlfix.
Hi dedlfix,
Im SELECT ist nur Abfragelogik anwendbar. Damit kann man keine Programme schreiben, die nicht vorhandene aber berechenbare Daten als Ergebnisdatensätze hinzufügen.
Ok, verstehe.
Ach, so herum meinst du das. Ja, das geht natürlich auch, das braucht dann "nur" 28 Abfragen und nicht 28 mal X. Das beschränkt die Anzahl doch mehr, also ich dacht. 28 ist aber trotzdem schon ganz ordentlich. Besonders wenn Netzwerk dazwischen liegt und das DBMS nicht auf derselben Maschine läuft.
Ok. Punkt 2 ist ja beeinflussbar. Und Punkt 1 ist maximal, ich glaube, 14 ist realistischer.
Kann ich denn per Prepared Statement noch etwas Performance gewinnen?
Pit
Tach!
Kann ich denn per Prepared Statement noch etwas Performance gewinnen?
Du kannst die Anzahl der Roundtrips reduzieren, beispielsweise die einzelnen SELECTS mit UNION zusammenfassen. Mit Stored Procedures würdest du in dem Fall auch nur etwas ähnliches machen, also wird da nichts weiter zu holen sein.
dedlfix.
Hallo dedlfix,
also ICH würde das mit einer Query lösen und die Tage nachher in der nachgelagerten Programmlogik abbilden.
Es gibt eine Menge Fälle (15, soweit ich weiß), wie sich zwei Zeiträume überlappen können, aber alle haben eins gemeinsam. Sei S der Suchzeitraum und T der Terminzeitraum, dann ist T relevant, wenn T.Ende >= S.Anfang UND T.Anfang <= S.Ende gilt. Oder andersrum mit de Morgan: T ist irrelevant, wenn T.Ende < S.Anfang ODER T.Anfang > S.Ende gilt.
Für die Treffer bildet man dann MAX(S.Anfang, T.Anfang) und MIN(S.Ende, T.Ende) und hat den gemeinsamen Bereich. Das kann man sogar schon vom SQL erledigen lassen.
Rolf
Hallo Rolf B,
Es gibt eine Menge Fälle (15, soweit ich weiß), wie sich zwei Zeiträume überlappen können,
Wie ist das gemeint?
|---T---|
|---S---|
|---T---|
|---S---|
|---T---|
|---S---|
|----T----|
|---S---|
|----T----|
|---S---|
|----T----|
|---S---|
|--T--|
|---S---|
|--T--|
|---S---|
|--T--|
|---S---|
Ich komm nur auf 9.
Bis demnächst
Matthias
Hallo Matthias,
sorry, hätte schreiben müssen: Wie sie zueinander in Beziehung stehen können.
S: <------------------>
T1: <-----> komplett davor
T2: <------------> Ende-T = Anfang-S
T3: <-----------------------> Beginn vor S, Ende in S
T4: <-------------------------------> Beginn vor S, Ende-T=Ende-S
T5: <----------------------------------------> T überdeckt S
T6: | T = Anfang S (T kein Zeitraum)
T7: <-----> Anfang-T=Anfang-S, Ende T in S
T8: <------------------> T=S
T9: <---------------------------> Anfang-T=Anfang-S, Ende hinter S
T10: <-----> T komplett innerhalb S
T11: <------------> Anfang-T in S, Ende-T=Ende-S
T12: <---------------------> Anfang-T in S, Ende-T hinter S
T13: | T=Ende S (T kein Zeitraum)
T14: <-----> Anfang-T = Ende S
T15: <-----> T komplett hinter S
Es sind eigentlich 18, aber die Fälle, wo T kein Zeitraum, sondern nur ein Zeitpunkt ist (also Anfang-T=Ende-T) und T komplett vor, in oder hinter S liegt, sind durch T1, T10 und T15 mit abgedeckt.
T2,4,6,7,8,9,11,13,14 brauchen besondere Aufmerksamkeit, weil hier zu entscheiden ist, ob ein <,> oder <=,>= gebraucht wird. Das kann außer Pit niemand entscheiden. In meinem Vorschlag bin ich von <=,>= ausgegangen.
Rolf
Hallo Rolf,
also ICH würde das mit einer Query lösen und die Tage nachher in der nachgelagerten Programmlogik abbilden.
OK, ich versuchs auch mal.
Es gibt eine Menge Fälle (15, soweit ich weiß), wie sich zwei Zeiträume überlappen können, aber alle haben eins gemeinsam. Sei S der Suchzeitraum und T der Terminzeitraum, dann ist T relevant, wenn T.Ende >= S.Anfang UND T.Anfang <= S.Ende gilt. Oder andersrum mit de Morgan: T ist irrelevant, wenn T.Ende < S.Anfang ODER T.Anfang > S.Ende gilt.
Kann es sein, dass in meinem Fall der Ansatz T.Ende > S.Anfang UND T.Anfang < S.Ende sein sollte? Das würde die beiden Termine des User 1 bereits herausfiltern. >= und <= würde die Termine des User 1 hingegen einbeziehen. (Oder würde Dein 2.Teil mit MAX und MIN diese Termine ebenfalls herausfiltern? Den Teil verstehe ich nämlich noch nicht ganz.)
Für die Treffer bildet man dann MAX(S.Anfang, T.Anfang) und MIN(S.Ende, T.Ende) und hat den gemeinsamen Bereich. Das kann man sogar schon vom SQL erledigen lassen.
Da ich diesen Teil noch nicht ganz verstehe: kannst du mir hierfür ein Beispiel geben, wie ich das in SQL umsetzen müßte?
Pit
Hallo Pit,
zu <,> vs <=,>= siehe meine Antwort von eben an Matthias. Das musst Du so wählen, wie es zu deinen Anforderungen passt.
Im SQL kannst Du das so machen:
SELECT t.Anfang, t.Ende,
(case when t.Anfang > $suchanfang then t.anfang else $suchanfang) as XAnfang,
(case when t.Ende < $suchende then t.ende else $suchende ) as XEnde,
-- weitere spalten
FROM termine t
WHERE t.Anfang <= $suchende AND t.Ende >= $suchanfang
Nimm das als Pseudocode, ich wollte nur zeigen wie du berechnete Spalten erzeugst und benennst. MAX und MIN als Funktionen kannst Du nicht verwenden, die sind für GROUP BY reserviert, daher das CASE-Konstrukt. Ich habe keine MYSQL Funktion gefunden, die Maximum oder Minimum zweier beliebiger Werte liefert. $suchanfang und $suchende stehen für PHP-Variablen, die diese Werte enthalten - die darfst Du natürlich nicht direkt aus dem HTML Formular übernehmen sondern musst sie entsprechend validieren. Ggf. auch umwandeln, je nach dem, wie Du deine Zeitpunkte in der Table speicherst. Und wenn Du diese Abfrage mehrfach machen musst, lohnt natürlich immer ein prepared statement.
Rolf
Hi Rolf,
danke für Deine Hilfe. Eines versteh ich nur nicht.
Meine Query:
SELECT DATE(t.Start), DATE(t.End),
(case when DATE(t.Start) > 2017-10-23 then DATE(t.Start) else 2017-10-23 END) as XAnfang,
(case when DATE(t.End) < 2017-11-05 then DATE(t.End) else 2017-11-05 END) as XEnde
FROM termine_termine t
ergibt:
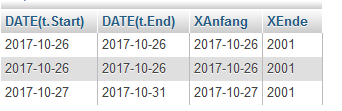
Wenn ich aberden "WHERE-Zusatz" nutze,
SELECT DATE(t.Start), DATE(t.End),
(case when DATE(t.Start) > 2017-10-23 then DATE(t.Start) else 2017-10-23 END) as XAnfang,
(case when DATE(t.End) < 2017-11-05 then DATE(t.End) else 2017-11-05 END) as XEnde
FROM termine_termine t
WHERE DATE(t.Start) <= 2017-11-05 AND DATE(t.End) >= 2017-10-23
kommt eine leere Ergebnismenge raus.
Dabei lägen doch die Ergebnisse innerhalb des "WHERE-Zusatzes", oder?
XEnde "2001" kann ich auch nicht wirklich zuordnen.
Pit
Hi,
SELECT DATE(t.Start), DATE(t.End), (case when DATE(t.Start) > 2017-10-23 then DATE(t.Start) else 2017-10-23 END) as XAnfang, (case when DATE(t.End) < 2017-11-05 then DATE(t.End) else 2017-11-05 END) as XEnde FROM termine_termine t
2017 - 10 - 23 ist 1984. Soll DATE(t.start) wirklich mit 1984 verglichen werden?
Normalerweise muß man doch eine Funktion to_date (bei Oracle, wie's bei MySQL oder so heißt, weiß ich nicht) nutzen, um aus einem Datums-Literal (das dabei ein String-Literal ist) ein Datum zur Verwendung in SQL zu machen, also sowas:
case when DATE(t.Start) > to_date('2017-10-23', 'yyyy-MM-dd')
und für die anderen Datums-Werte entsprechend.
Und warum DATE(t.start)? Ist start etwa keine Datumsspalte?
XEnde "2001" kann ich auch nicht wirklich zuordnen.
2017 - 11 = 2006, 2006 - 5 ist 2001.
Hast Du doch in Deinem zweiten case when Date(t.End) so hingeschrieben: 2017-11-5, was nunmal 2001 ergibt. Simple Grundschul-Mathematik.
cu,
Andreas a/k/a MudGuard
Hallo Andreas,
danke für die beiden Hinweise.
Wenn man beides ändert, klappts auch mit der Query.
Es t.Start und t.Ende sind beides datetime-Spalten und die (sql)Funktion heißt STR_TO_DATE.
Pit
Hallo Pit,
es ist eine gute Frage, wie man sowas macht. In meinem Handy-Kalender kann ich auch sagen: "Jeden Mittwoch", und habe dann Termine am Mittwoch bis zum St. Nimmerleinstag. Und dann kann ich an irgendeinem Mittwoch sagen: "Diesen Termin löschen, aber nicht die Serie". Würde der Kalender im Handy nur einen Basistermin führen und den Rest davon ableiten, bräuchte man sowas wie einen "Anti-Termin", um ein "immer aber nicht DANN" zu realisieren. Klingt kompliziert.
Besser wäre wohl, Termin und Zeitraum getrennt zu modellieren. Ein Termin existiert einmal, kann aber beliebig viele Zeiträume haben. Um einen Zeitraum [x,y] im Kalender darzustellen, sucht das Kalenderprogramm alle Zeiträume, deren Beginn vor y UND deren Ende hinter x liegt. Ein BETWEEN ist das nicht. Die so gefundenen Termine muss man nun genauer betrachten: Wer ist ein Serientermin, wie ist die Serienregel, um im darzustellenden Zeitraum die richtigen Instanzen anzuzeigen.
Soll nun eine Serie unterbrochen werden (also ein Termin jeweils am 1. des Monats, beginnend ab 01.01.2017, Ende offen - und die Instanz am 01.11.2017 wird abgesagt), dann beendest Du den Zeitraum, in dem der 01.11. lag, am 31.10 (oder am 01.10.) und beginnst am 01.12. einen neuen Zeitraum. Macht man das mehrmals, kann das zu Zeiträumen führen die gar keinen Termin mehr enthalten - die kannst Du dann löschen.
Die getrennte Modellierung von Termin und Zeitraum erlaubt es dann auch, den Termin selbst zu ändern (Grund, Ort, Teilnehmer) und die Änderungen sofort in allen Instanzen des Termins darstellbar zu machen. Würde man Termin und Zeitraum in einer Tabelle führen, müsste man für solche ausfallenden Serieninstanzen den kompletten Termin klonen und hätte dann das Problem, Änderungen synchron zu halten.
Rolf
Tach!
In meinem Handy-Kalender kann ich auch sagen: "Jeden Mittwoch", und habe dann Termine am Mittwoch bis zum St. Nimmerleinstag. Und dann kann ich an irgendeinem Mittwoch sagen: "Diesen Termin löschen, aber nicht die Serie". Würde der Kalender im Handy nur einen Basistermin führen und den Rest davon ableiten, bräuchte man sowas wie einen "Anti-Termin", um ein "immer aber nicht DANN" zu realisieren. Klingt kompliziert.
Sieht so aus, dass es genau so im Kalenderformat ICS gemacht wird.
BEGIN:VEVENT
DTSTART:20171002T000000Z
DTEND:20171003T000000Z
RRULE:FREQ=DAILY;UNTIL=20171006T000000Z;INTERVAL=1
EXDATE:20171003T000000Z
UID:20171025T101132Z-37
DTSTAMP:20171025T101132Z
SUMMARY:Foo
DESCRIPTION:
END:VEVENT
Das ist ein Ganztagestermin vom 2.10. 0 Uhr bis 3.10. 0 Uhr (DTSTART und DTEND). Wiederholung (RRULE) bis 6.10. alle 1 Tage, also täglich. Ausnahme (EXDATE): 3.10.
dedlfix.
BEGIN:VEVENT DTSTART:20171002T000000Z DTEND:20171003T000000Z RRULE:FREQ=DAILY;UNTIL=20171006T000000Z;INTERVAL=1 EXDATE:20171003T000000Z UID:20171025T101132Z-37 DTSTAMP:20171025T101132Z SUMMARY:Foo DESCRIPTION: END:VEVENTDas ist ein Ganztagestermin vom 2.10. 0 Uhr bis 3.10. 0 Uhr (DTSTART und DTEND). Wiederholung (RRULE) bis 6.10. alle 1 Tage, also täglich. Ausnahme (EXDATE): 3.10.
Hi dedlfix, danke für die Ergänzung. Pit
Hi dedlfix, Hi Rolf,
Sieht so aus, dass es genau so im Kalenderformat ICS gemacht wird.
BEGIN:VEVENT DTSTART:20171002T000000Z DTEND:20171003T000000Z RRULE:FREQ=DAILY;UNTIL=20171006T000000Z;INTERVAL=1 EXDATE:20171003T000000Z UID:20171025T101132Z-37 DTSTAMP:20171025T101132Z SUMMARY:Foo DESCRIPTION: END:VEVENTDas ist ein Ganztagestermin vom 2.10. 0 Uhr bis 3.10. 0 Uhr (DTSTART und DTEND). Wiederholung (RRULE) bis 6.10. alle 1 Tage, also täglich. Ausnahme (EXDATE): 3.10.
Bei mir bleibt eine Frage hierzu offen: Mache ich verschiedene Zeiträume je Termin möglich oder führe ich nur 1 Zeitraum, dafür Exirationdates mit?
Wie würde das im ICS Format eigentlich aussehen, wenn sowohl der 3.10 als auch der 5.10 von der Regel ausgenommen sein würden?
Und wie würde ein täglicher Termin aussehen, der aber die Wochenenden ausnimmt?
Pit
Tach!
Mache ich verschiedene Zeiträume je Termin möglich oder führe ich nur 1 Zeitraum, dafür Exirationdates mit?
Ich würde das dem Anwender überlassen, wie er die Termine in der Komponente verwaltet. Und dann müsste man schauen, wie die Komponente ihre Daten hergibt und haben möchte. Selbst schreiben würde ich den Kalender jedenfalls nicht wollen. Auch kennen die Anwender vielleicht schon Outlook oder ähnliche Prgramme und wie dort Serientermine erstellt werden. Das erspart Einarbeitungsaufwand, wenn die Komponente das in vergeichbarer Form macht.
Wie würde das im ICS Format eigentlich aussehen, wenn sowohl der 3.10 als auch der 5.10 von der Regel ausgenommen sein würden?
Probier es aus. Du kannst dazu im Prinzip jedes Kalenderprogramm verwenden, das exportieren kann. Ich habe dazu eine online verfügbare Demo der Telerik-Komponente namens Scheduler verwendet (Suchstichwörter: telerik scheduler demo). Diese Telerik-Komponenten gibt es für viele Programmierplattformen, aber das ist für deinen Fall erstmal nebensächlich. Du brauchst dir nur die Demo mit dem Export zu suchen. Die erzeugt jedenfalls die ICS-Dateien oder auch andere Formate, und du brauchst dann nur noch eine Texteditor, um dir die Ergebnisse anzuzeigen.
dedlfix.
Hi dedlfix,
ok, habe 2 Kalender gefunden, die das können.
Dann schaun mer mal 😉
Pit
Hallo Pit,
Wie würde das im ICS Format eigentlich aussehen, wenn sowohl der 3.10 als auch der 5.10 von der Regel ausgenommen sein würden?
Bis demnächst
Matthias
Hallo Pit,
Wie würde das im ICS Format eigentlich aussehen, wenn sowohl der 3.10 als auch der 5.10 von der Regel ausgenommen sein würden?
- https://icalendar.org/RFC-Specifications/iCalendar-RFC-5545/
- https://icalendar.org/RFC-Specifications/New-Properties-for-iCalendar-RFC-7986/
Bis demnächst
MatthiasRosen sind rot.
Hallo Matthoias,
danke, habe ich mir schon rausgesucht.
Pit
Hello,
Sieht so aus, dass es genau so im Kalenderformat ICS gemacht wird.
BEGIN:VEVENT DTSTART:20171002T000000Z DTEND:20171003T000000Z RRULE:FREQ=DAILY;UNTIL=20171006T000000Z;INTERVAL=1 EXDATE:20171003T000000Z UID:20171025T101132Z-37 DTSTAMP:20171025T101132Z SUMMARY:Foo DESCRIPTION: END:VEVENT
Danke für den Tipp. (+)
Also sollte man sich doch neben allem eigenen Design zuerst mal mit dem Protokoll des ICS beschäftigen, da das vermutlich bei vielen Kalendern (Thunderbird?) funktioniert?
Liebe Grüße
Tom S.
Tach!
Also sollte man sich doch neben allem eigenen Design zuerst mal mit dem Protokoll des ICS beschäftigen, da das vermutlich bei vielen Kalendern (Thunderbird?) funktioniert?
Das war das Format, das mir als erstes über den Weg lief. Ich nehme an, dass es zumindest ein Format ist, mit dem alle Major-Player umgehen können.
dedlfix.
Hallo Rolf,
Die getrennte Modellierung von Termin und Zeitraum erlaubt es dann auch, den Termin selbst zu ändern (Grund, Ort, Teilnehmer) und die Änderungen sofort in allen Instanzen des Termins darstellbar zu machen.
Danke für Deine Denkanstöße. Sehr sinnvoll, finde ich.
Pit
Hallo Pit,
danke für das Lob, aber offenbar ist der Industrie Standard ICS ja anderer Meinung. DAS habe ich vorher nicht recherchiert. Du musst abwägen, ob dir ein Standard wichtig ist.
Rolf
Hallo Pit,
danke für das Lob, aber offenbar ist der Industrie Standard ICS ja anderer Meinung. DAS habe ich vorher nicht recherchiert. Du musst abwägen, ob dir ein Standard wichtig ist.
Hallo Rolf,
hilf mir mal auf die Sprünge: Wo siehst Du die Diskrepanz zwischen Deinen Denkanstößen und dem ICS? Nur darin, dass Du einen Termin in n Zeitspannen unterteilen würdest, während der ICS Expiredates setzen würde? Das alleine würde doch die Sinnhaftigkeit Deiner Denkanstöße in keiner Weise schmälern. Oder siehst Du noch Dinge, die ich nicht sehe?
Pit
Tach!
Nur darin, dass Du einen Termin in n Zeitspannen unterteilen würdest, während der ICS Expiredates setzen würde?
Ex wie in Exclude trifft es eher.
dedlfix.
Hallo Pit,
Sinn ist eine Sache, Praktikabilität eine andere. Für mich erschien die Idee von ICS nicht praktikabel. Anderen wohl doch, und es wurde ein erfolgreicher Standard daraus. Heißt: ich hab mich da wohl vergaloppiert.
Rolf
Hallo Rolf,
Sinn ist eine Sache, Praktikabilität eine andere. Für mich erschien die Idee von ICS nicht praktikabel. Anderen wohl doch, und es wurde ein erfolgreicher Standard daraus. Heißt: ich hab mich da wohl vergaloppiert.
Da bin ich irgendwie ganz anders gepolt. Und ich sehe es auch komplett anders. Deine Selbstreflektion in Ehren, aber das aus einem anderen Denkansatz ein erfolgreiches System wird, liegt an vielen Dingen. Die Qualität ist nur ein Faktor von vielen. Betamax und Video2000 erschienen ihre Systeme zur Videoaufzeichnung richtig, VHS wurde aber ein erfolgreicher Standard. Waren deshalb Betamax und Video2000 schlechter? Nein, das Gegenteil war der Fall. Dennoch wurde VHS der Standard.
Deshalb: Auch wenn ICS ein erfolgreicher (ich würde es eher als einen notwendigen bezeichnen) Standard ist, kann er minder praktikabel sein, als ein anderer Denkansatz. Wenn ähnlich viele Entwickler einen anderen (z.b. Deinen) Ansatz weiter verfolgt hätten, könnte genausogut dieser der heute erfolgreiche Standard sein.
Deshalb passt "vergaloppiert" IMHO hier nicht. Davon ab...es ging hier um einen Weg für mich und womöglich (das weiß heute keiner) wäre Dein Ansatz für mich durchaus praktikabler.
Pit
Hi,
Besser wäre wohl, Termin und Zeitraum getrennt zu modellieren.
Noch besser: Zeiträume als Eigenschaften von Terminen bzw. Ereignissen. Ereignisse können sehr unterschiedliche und beliebig viele Eigenschaften haben, das macht ein DB-Design schwierig insbesondere wenn sich neue Anforderungen ergeben (z.B. Dateianlagen, Kommentare, Personen). Objektorientiert hingegen kommt die Datenhaltung besser mit Veränderungen zurecht.
MfG
Hallo pl,
nein, ein Zeitraum ist keine Eigenschaft im Sinne eines irgendwie normalisierten Datenbankmodells. Damit verletzt Du die 1. Normalform. Für eine schnelle, SQL-gestützte Suche in der Datenbank muss man Beginn und Ende eines Zeitraums ausmodellieren. Eine Liste von Zeiträumen verlangt eine Auslagerung dieser Attribute in eine Extratabelle, sonst ist ebenfalls 1NF verletzt.
Und nochmal nein, eine grundsätzliche Speicherung eines Kalenders als EAV würde ich nicht empfehlen.
Eine Speicherung von Extraattributen, die nur bei wenigen Terminen eingegeben werden, dagegen schon. Die gehören in eine EAV-Tabelle.
Rolf
hi,
nein, ein Zeitraum ist keine Eigenschaft im Sinne eines irgendwie normalisierten Datenbankmodells.
Richtig. Vielmehr sind Zeiträume Eigenschaften von Ereignissen. Z.B. die Dauer einer Veranstaltung oder die Lebensdauer zyklischer Termine oder Beginn und Ende einer Epoche. Das Ereignis ist das Datenmodell.
MfG
 TS
TS Rolf B
Rolf B Matthias Apsel
Matthias Apsel MudGuard
MudGuard