


MIPS Branch Hazards
Julia
- sonstiges
 nicht angemeldet
nicht angemeldetHallo Forum,
gegeben sind:
loop: addi $a0, $a0, 4
lw $v0, 0($a0)
beq $v0, $zero, loop
move $v0, $a0
j end
array: .word 0,0,1,1,0,2,3,0 #Array von 32-Bit-Worten Länge 8
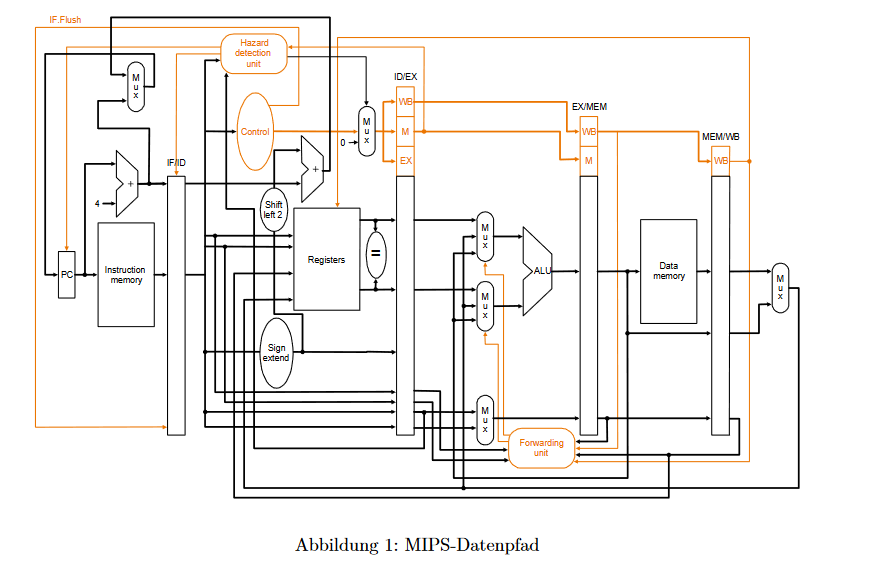
Und ich muss eine Tabelle ausfüllen, welcher Teil der Pipline zum welchem Takt mit welcher Instruktion beschäftigt ist:
| Zyklus| IF | ID | EX | MEM | WB |
a) Ohne Branch Delay Slot b) Mit 1-Branch Delay Slot
Erstmal meine Überlegungen: Da wir FU haben, entsteht kein Konflikt zwischen Zeilen addi / lw. Richtig? D.h. wir können wie folgt angangen:
| Zyklus| IF | ID | EX | MEM | WB | |0|addi| |1|lw|addi |2|beq|lw|addi
Die Zeilen lw / beq verursachen einen Konflikt, weil beq auf $v0 zugreifen muss, und lw $v0 noch nicht geschrieben hat. Dieser Konflikt wird durch HDU erkannt. D.h. wir müssen Stalling anwenden (also 1 nop einfügen). Ich weiß wohl nicht, wie ich das am sinnvollsten in der Tabelle darstellen soll, ich versuche mal so:
| Zyklus| IF | ID | EX | MEM | WB | |0|addi| |1|lw|addi |2|beq|lw|addi |3|(move)|(beq)|lw|addi |4|move|beq|nop|lw|addi
Die nächste "Problemstelle" ist in den Zeilen beq / move. An der Stelle kommt es (wahrscheinlich) darauf an, ob wir einen Branch Delay Slot haben oder nicht.
Zum Thema wurden uns verschiedene Strategien für die Entscheidung über den Sprung vorgestellt.
Aber wir sieht es in diesem Fall aus? Ich gehe davon aus, dass wir keinen BTB haben. Dann:
| Zyklus| IF | ID | EX | MEM | WB | |0|addi| |1|lw|addi |2|beq|lw|addi |3|(move)|(beq)|lw|addi |4|move|beq|nop|lw|addi |5|(j)|(move)|beq|nop|lw| |6|j|move|nop|beq|nop|
Ist es korrekt? Oder brauchen wir hinter dem beq 2 x nop? Ich bin mir leider sehr unsicher, weil wir das in der Form nie besprochen hatten, aber ich muss das trotzem für Klausur können.
D.h. am Ende würde der Code so aussehen:
loop: addi $a0, $a0, 4
lw $v0, 0($a0)
nop
beq $v0, $zero, loop
nop
move $v0, $a0
j end
array: .word 0,0,1,1,0,2,3,0 #Array von 32-Bit-Worten Länge 8
Was wäre der Unterschied, wenn wir Branch Delay Slot hätten?
Ich vermute, dass man in diesem Fall den Code umordnen könnte / sollte. Ich habe mir überlegt, dass man addi nach Hinten verlegen könnte, wenn man den Offset anpasst:
loop: lw $v0, 4($a0)
beq $v0, $zero, loop
addi $a0, $a0, 4
move $v0, $a0
j end
array: .word 0,0,1,1,0,2,3,0 #Array von 32-Bit-Worten Länge 8
Ist die Idee richtig?
Schönen Dank im Voraus!
Julia
Hallo Julia,
sorry, da komme ich nicht wirklich mit. Ich kann zwar Vermutungen anstellen, aber so tief in der technischen Informatik bin ich nicht (mehr) drin, dass ich hier verbindlich was sagen kann. Gerade die Techniken beim Pipelining kenne ich nur oberflächlich.
Ich kann den Assembler-Code soweit deuten, dass hier das erste Element gesucht wird das nicht $zero ist (also hoffentlich nicht 0 ist) und dessen Adresse in $v0 hinterlassen wird. $a0 muss so initialisiert werden, dass es 4 Bytes vor den Listenbeginn gesetzt wird - oder das erste Element wird nicht beachtet.
Was eine FU genau tut und warum sie die Abhängigkeit zwischen dem addi und lw auflöst - keine Ahnung. Kurzes googlen sagt mir aber, dass sie wohl genau das tut was Du geschrieben hast. Weshalb die FU beim Schreiben auf $a0 wirkt, aber beim Schreiben auf $v0 nicht, so dass der nop nötig wird - keine Ahnung. Ich musste ja auch erstmal googeln was $a0 und $v0 überhaupt sind :)
Deinen Überlegungen zum Stalling, BPB und BTB kann ich überhaupt nicht folgen. Nicht wegen der Qualität deines Textes, sondern weil ich die verwendeten Prinzipien nicht gut genug kenne. Ein Intel-Prozessor würde hier vermutlich mit Register Renaming arbeiten, um einen potenziell falschen move nach $v0 verwerfen zu können.
Deine letzte Code-Umordnung (mit 4($a0)) dürfte aber falsch sein. Sie führt meines Erachtens auf eine Endlosschleife, wenn der erste Wert der Liste 0 ist. Unbekannt ist mir, ob der Prozessor eine Adresse 0($a0) genauso schnell bearbeitet wie 4($a0). Letzeres braucht eine zusätzliche Addition, ersteres ggf. nicht, es kommt also darauf an, ob es für 0($a0) eine optimierte Instruktion gibt bzw. ob die Adressierung im Data Fetch Offsets ohne Zeitverlust verarbeiten kann.
Rolf
Hallo Rolf,
schönen Dank für deine Antwort und entschuldige, dass ich erst jetzt antworte.
Mit der Aufgabe bin ich bis zur Klausur nicht wirklich warm geworden, aber das Prinzip habe ich wohl richtig erkannt.
Die Klausur ist also trotzdem recht gut gelaufen und ich habe eine 1,7 und bin sehr zufrieden🌝
Noch mal danke und viele Grüße
Julia
Hallo Julia,
1,7 ist top, herzlichen Glückwunsch.
Rolf
 Rolf B
Rolf B