Hallo Rolf,
so, bin auch wieder da. Musste in Telefonkonferenzen, dann Heimfahrt aus dem Büro, Einkaufen, Star Trek Discovery gucken, Biathlon Herrenstaffel gucken, viel zu tun 😂
Ja, das kann ich natürlich verstehen 😀
Ich hatte auch schon gestern abend gesehen, dass der Reiter neue Antworten anzeigte, aber da ich über diesen Rechner grad Pastewka über meine Vu+ auf den Familien-TV streamte, konnte ich erst heute morgen in Eure Antworten hinein schauen.
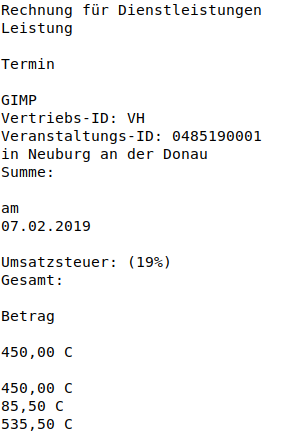
Die letzte Regex die ich von Dir sehe (mit Modifikation von Jörg), ist:
/^(?<startwort>AB[\w\d]+[a-zA-Z-]*)\s+(?<startplus>(AB[\w\d-]+[,]*\s+)*)(?<vorwort>.*)\s+(?<zahl>\d+)\s+(?<wort>[a-zA-Z0-9_üöä]+)\s+(?<betrag>[\d.,]+)\s*$/
Ich muß Jörg da in Schutz nehmen, von ihm kommt die -Erweiterung im <startwort>, der Rest ist auf meine Versuche zurückzuführen.
#1. (?<startwort>AB[\w\d]+[a-zA-Z-]*)
Das [a-zA-Z-]* hintendran ist sinnlos, das wird vom [\w\d]+ davor schon mit gematcht. Bring das Minus einfach in die Buchstaben/Ziffernfolge hinein. Und ich wette, dass irgendwer auch noch ein Komma hinter's Startwort gemacht hat. Und ein Ober-Experte hat garantiert noch ein Deppen-Space VOR das Komma gemacht. Oder vielleicht gar kein Space, nur ein Komma. Null Problemo, das matchen wir alles:
(?<startwort>AB[\w\d-]+)(\s*,\s*|\s+)
Liest sich so: AB, dann 1-n Buchstaben,Ziffern,Minusse, dann ENTWEDER ein durch optionale Spaces eingeschlossenes Komma ODER mindestens ein Space. Leerraum und Komma sind nicht Teil der benannten startwort-Gruppe.
Hm... ist das so richig?
Ich suche: AB, dann 0 bis n Buchstaben, gefolgt von 1-n Ziffern, gefolgt von 0 bis n Buchstaben,Ziffern,Minusse...
So vielleicht: (?<startwort>AB[\w]*[\d-]+[-\w]*)(\s*,\s*|\s+)
Allerdings generiert der Online-Regtester bei mir dann wieder eine Gruppe2 😟
Ich finde diesen Ausdruck, so er denn korrekt ist, weniger gierig.
#2. (?<startplus>(AB[\w\d-]+[,]*\s+)*)
Jörg hatte das [,]* empfohlen, was „am Ende 0-n Zeichen der Kategorie Komma“ bedeutet. Kann man machen, aber ich würd's so machen wie beim Startwort:
(?<startplus>(AB[\w\d-]+(\s*,\s*|\s+))*)
Hier ist der Trennbereich im startplus-Match mit drin, das lässt sich nicht vermeiden. PHP kennt keine Match-Arrays, d.h. sowas wie ((?<startplus>AB\d+)(\s*,\s*|\s+))* würde unter startplus nicht die gefundenen Worte als Array ablegen, sondern nur das letzte startplus-Wort. Wenn du die startplus-Worte einzeln brauchst, musst Du das separat zerlegen.
Zum einen dieselbe Frage wie oben schon: Soll ich den weniger gierigen Ausdruck verwenden?
Und zum zweiten: nein, ich brauche die unter startplus gefundenen Wörter definitiv nicht einzeln, die Gruppe reicht völlig aus.
#3. ABBILD
Den rauszufieseln ist kaum möglich, es sei denn, du kannst definieren, dass die Codewörter immer mindestens eine Ziffer hinter dem AB enthalten. Dann könnte man die Codewörter so matchen: statt AB[\w\d-]+ nimmt man (AB[\w\d-]*\d[\w\d-]*
Die AB-Wörter haben immer nach dem 3.Zeichen eine oder mehrere Ziffern. Das 3. zeichen kann wahlweise auch ein Buchstabe sei (aber kein Minus o.ä.), aber ab dem 4. Zeichen kommen erstmal 1-n Ziffern, bevor dann 0-n Minusse,Buchstaben,Ziffern folgen können.
Häßlichkeiten wie „AB-4711“ oder „ABB1LD-“ würden davon auch erfasst.
Stimmt, aber nach der Information oben nun nicht mehr.
#4. non-capturing groups
Ein kleiner Hinweis am Rand, falls dich die unbenannten Match-Gruppen nerven. Sowas kann man abblocken, indem man hinter der öffnenden Klammer ein ?> notiert, also (?>AB\d+) statt (AB\d+).
Eigentlich nerven die mich gar nicht so sehr, ich hatte es nur angemerkt, dass die entstehen. Ich konnte damit nichts anfangen.
Ich habe das alles in deine regex101 Session eingetragen: https://regex101.com/r/VcgXCb/7
Sehr, sehr cool!
Aber ich sagte ja bereits... der helle wahnsinn! 😀
#5. Wie macht man das eleganter?
Solche Regexe sind unübersichtlich und haben Teile, die sich wiederholen. Das ist lästig und bei Änderungen fehleranfällig. In PHP kann man das Pattern auch aus Teilsegmenten zusammensetzen (ich hoffe, ich vertippe mich jetzt nicht). Um die Variablen im Gewühl besser zu erkennen, würde ich hier die komplexe String-Parsing Syntax von PHP empfehlen (also geschweifte Klammern). Zumindest coloriert der PHP-Parser des Forums damit deutlich besser:
$codewort = "AB[\w\d-]*\d[\w\d-]*";
$codespace = "(?>\s*,\s*|\s+)";
$keyword = "(?<wort>[a-zA-Z0-9_üöä]+)";
$betrag = "(?<betrag>[\d.,]+)";
$pStartWort = "(?<startwort>{$codewort}){$codespace}";
$pStartPlus = "(?<startplus>(?>{$codewort}{$codespace})*)";
$pZwischenteil = "(?<vorwort>.*)\s+(?<zahl>\d+)";
$pattern = "/^{$pStartWort}{$pStartPlus}{$pZwischenteil}\s+{$keyword}\s+{$betrag}\s*$/";
Ob es Dir mit oder ohne {} besser gefällt ist deine Sache. Ich finde es {so} lesbarer.
Ja, so ist es wirklich viel lesbarer... aber ich habe den Online-Regtester durchaus schätzen gelernt. Und da müßte ich mir dann jedesmal die Regex hieraus wieder zusammenschustern, oder?
Pit



 Matthias Apsel
Matthias Apsel
 Rolf B
Rolf B
 dedlfix
dedlfix
 Gunnar Bittersmann
Gunnar Bittersmann MudGuard
MudGuard