


strtolower niemals nutzen, veraltet?
 Henry
Henry
- konvertierung
- php
- unicode
 nicht angemeldet
nicht angemeldetHallo,
mir fiel ein seltsames Verhalten bei strtolower() auf.
$str = 'Der Schäfer hütet die Schafe';
$str = strtolower($str);
echo $str;
Daraus wird, obwohl alles UTF-8, dieses:
der sch�fer h�tet die schafe
Nun weiss ich zwar, dass strtolower keine Umlaute umwandeln kann, hatte aber erwartet, dass diese dann dennoch normal erscheinen.
Dennoch funktioniert eine Suche mit strpos() offensichtlich problemlos, sofern der Suchbergriff ebenso mit strtolower behandelt wird:
strpos($str, strtolower(Schäfer));
Also sch�fer findet sch�fer.
Bisher ist mir das so nie aufgefallen, weil im normalen Gebrauch suche ich etwas im Text und lasse mir danach die Passage aus dem Originaltext anzeigen, wo dann die Hieroglyphen nicht auftauchen.
Nun stelle ich mir aber die Frage, wie schnell ich mir Probleme damit einhandeln könnte, denn vergesse ich das mal irgendwann an einer Stelle, also bspw. ich nehme den Suchtext und mache alles klein, das suchwort aber formatiere ich nicht, weil sowieso klein, dann habe ich keine Treffer. Wer weiss ob mir das nicht bisher schon irgendwo passiert ist. schäfer findet nicht sch�fer.
Im Manual habe ich dann in den Kommentaren eine Funktion gefunden, die das ändert aber auch schon uralt ist und zudem den Nachteil hat, dass man auch alles damit konvertieren muss, wobei ich nicht mal getestet habe was passiert, wenn kein UTF-8 vorliegt. Na ja, dann fiel mir ein da war ja auch eine andere Möglichkeit, mb_strtolower().
Ich vermute mal, und das ist die eigentliche Frage hier, ich sollte immer diese anstatt strtolower() verwenden, oder gibt es Ausnahmen?
Denn normalerweise warnt das Manual plakativ doch vor veralteten/nicht_sinnvollen Sachen, daher der Gedanke es gibt vielleicht doch manchmal Gründe strtolower den Vorzug zu geben?
Und wenn das so ist, auch immer mit dem Argument UTF-8 mb_strtolower($str, 'UTF-8');, oder spricht da was dagegen?
Gruss
Henry
Hello,
strtolower() ist für Singlebytecode, und zwar für ISO8859-1 das Hilfsmittel gewesen, die gemeinen Äquivalenzen zu Versalien zu finden. 1 blieb also immer noch 1, aus Ü wurde aber ü.
Wenn Du nun Multibytecodierungen, wie z. B. UTF-8 benutzt, musst Du auch eine geeignete Funktion dafür verwenden, die gemeinen Äqzivalenzen zu finden. Dafür wurde mb_strtolower() geschaffen. Dieser Funktion musst Du aber entweder mittels Voreinstellung, oder aber explizit die Codierung mitteilen!
Wenn Du also nun in eine neue Webseite, die mif UTF-8 arbeitet, Code aus anderen, Quellen die noch mit ISO8859 arbeiten, einbinden willst, musst Du das den in Frage kommenden mb_*-Funktionen mitteilen.
Glück Auf
Tom vom Berg
Tach!
Wenn Du also nun in eine neue Webseite, die mif UTF-8 arbeitet, Code aus anderen, Quellen die noch mit ISO8859 arbeiten, einbinden willst, musst Du das den in Frage kommenden mb_*-Funktionen mitteilen.
Ich würde beim Übernehmen der Daten bereits diese nach UTF-8 kodieren, damit im weiteren Verlauf der Code durchweg mit einer Kodierung arbeiten kann und man nicht auf Umkodierungen aufpassen muss.
dedlfix.
Hello,
Wenn Du also nun in eine neue Webseite, die mif UTF-8 arbeitet, Code aus anderen, Quellen die noch mit ISO8859 arbeiten, einbinden willst, musst Du das den in Frage kommenden mb_*-Funktionen mitteilen.
Ich würde beim Übernehmen der Daten bereits diese nach UTF-8 kodieren, damit im weiteren Verlauf der Code durchweg mit einer Kodierung arbeiten kann und man nicht auf Umkodierungen aufpassen muss.
Man sollte hier aber strikt die beiden Datenpfade "holen, verarbeiten, (wieder) wegschreiben" und "holen, verarbeiten, anzeigen" unterscheiden. Bei welchem der beiden Pfade würdest Du denn bedenkenlos bereits nach dem Holen die Codierungsumwandlung vornehmen?
Ich bin da immer vorsichtig mit Pauschalempfehlungen. ;-)
Glück Auf
Tom vom Berg
Tach!
Ich würde beim Übernehmen der Daten bereits diese nach UTF-8 kodieren, damit im weiteren Verlauf der Code durchweg mit einer Kodierung arbeiten kann und man nicht auf Umkodierungen aufpassen muss.
Man sollte hier aber strikt die beiden Datenpfade "holen, verarbeiten, (wieder) wegschreiben" und "holen, verarbeiten, anzeigen" unterscheiden. Bei welchem der beiden Pfade würdest Du denn bedenkenlos bereits nach dem Holen die Codierungsumwandlung vornehmen?
Ich wüsste nicht wo da der Unterschied sein soll. Anzeigen ist auch nur eine Art von Wegschreiben. Die Daten werden an ein System weggeschrieben, das sie anzeigen soll. Ob es stattdessen ein System ist, das eine andere Verarbeitung vornimmt, ist dabei egal. In jedem Fall muss das Zielsystem korekt kodierte Daten (plus gegebenenfalls Metainformation) übergeben bekommen.
Ich bin da immer vorsichtig mit Pauschalempfehlungen. ;-)
Solange kein konkretes Szenario genannt ist, kann ich nur empfehlen, was (nach meinem Dafürhalten) üblicherweise das beste ist. Zudem fällt mir auch grad nicht ein, wo das EVA-Prinzip von generellem Nachteil wäre.
dedlfix.
Hello,
Achtung Nebelkerze! :-(
Wenn Daten aus dem Quellsystem in ein Verarbeitungssystem mit übergeordneter Codierung geladen werden, sollte man sie in ihrem Rohzustand und der untergeordneten Codierung belassen, nach den Regeln des untergeordneten Systems verarbeiten und dann auch so roh wieder an das untergeordnete System zurückgeben. Ein generelles Anheben auf den Zeichenvorrat des Obersystems birgt immer die Gefahr, dass beim Verarbeiten Varianzen entstehen, die beim Zurückschreiben nicht mehr eindeutig dem Zeichenvorrat des Zielsystems zuzuordnen sind.
Verschlüsselung ist hier ein häufiger Fehlerbereich.
Die kontextgerechte Behandlung findet erst bei der Ausgabe im Obersystem statt!
Glück Auf
Tom vom Berg
Tach!
Wenn Daten aus dem Quellsystem in ein Verarbeitungssystem mit übergeordneter Codierung geladen werden, sollte man sie in ihrem Rohzustand und der untergeordneten Codierung belassen, nach den Regeln des untergeordneten Systems verarbeiten und dann auch so roh wieder an das untergeordnete System zurückgeben. Ein anheben auf den Zeichenvorrat des Obersystems birgt immer die Gefahr, dass beim Verarbeiten Varianzen entstehen, die beim Zurückschreiben nicht mehr eindeutig dem Zeichenvorrat des Zielsystems zuzuordnen sind.
Ja, Daten lediglich durchzureichen ist eine Ausnahme. Dabei fällt die Verarbeitung weg und man braucht sie nicht im Rohformat. Gegebenenfalls braucht es aber eine Umkodierung als Anpassung zwischen Quelle und Ziel.
Allerdings tritt dein beschriebenes Szenario bei ISO-8859 als Ausgangs- und/oder Zielkodierung normalerweise nicht auf, weil das so wenig Zeichen kodieren kann, dass da beispielsweise nicht das Luxusproblem von Unicode auftritt, für das man Normalisierung benötigt. Ein Umlaut ist da ein Zeichen und nicht entweder ein eigenes Zeichen oder eine Kombination aus Grundzeichen plus Diakritika.
dedlfix.
Hello,
tut mir leid, immer noch Ndbelkerze!
Ich empfehle Dir da mal die diversen Artikel zur richtigen kontextbezogenen Behandlung von Daten ;-P
Es geht doch darum an welcher Stelle diese Behandlung stattzufinden hat. Deine Empfehlung in diesem Thread, diese Behandlung pauschal bereits direkt nach dem Holen durchzuführen, ist falsch!
Glück Auf
Tom vom Berg
Tach!
Ich empfehle Dir da mal die diversen Artikel zur richtigen kontextbezogenen Behandlung von Daten ;-P
Wenn der Kontext meines verarbeitenden Systems UTF-8 ist, dann findet der Kontextwechsel am Eingang zu diesem System statt.
Wenn das System in verschiedenen Kontexten arbeitet, muss man für die Übergänge dazwischen spezielle Lösungen suchen. Es macht die Sachlage aber nicht einfacher, wenn man nicht versucht, eine solche Komplexität zu vermeiden. Das Prinzip ist ja nicht deswegen schlecht, weil es ein paar Ausnahmen gibt, für das es nicht anzuwenden geht.
Es geht doch darum an welcher Stelle diese Behandlung stattzufinden hat. Deine Empfehlung in diesem Thread, diese Behandlung pauschal bereits direkt nach dem Holen durchzuführen, ist falsch!
Ich empfinde deine Aussagen auch nicht als weniger pauschal als meine. Meine Aussage war vor allem auf das Szenario des OP und vergleichbare bezogen. Deine Gegenantwort berücksichtigt auch nicht sämtliche Spezialfälle.
dedlfix.
Tach!
mir fiel ein seltsames Verhalten bei strtolower() auf. [...] Daraus wird, obwohl alles UTF-8, dieses:
Nicht obwohl, sondern weil. Die Stringfunktionen von PHP sind nur auf Ein-Byte-Kodierungen ausgelegt. Sie stammen aus einer Zeit, bevor Unicode/UTF-8 populär wurde und sind seitdem nicht mehr angefasst worden. Zum einen hätte man recht viele Inkompatibilitäten in PHP gebracht, zum anderen stellte sich der Umstellungsversuch als sehr schwierig heraus. Deswegen ist auch Version 6 gescheitert, und Version 7 hat immer noch keine durchgängige Unicode-Unterstützung an Bord.
Nun weiss ich zwar, dass strtolower keine Umlaute umwandeln kann, hatte aber erwartet, dass diese dann dennoch normal erscheinen.
Du hast da wohl einen Fehler im Versuchsaufbau. Die betroffenen Umlaute sind ja bereits Kleinbuchstaben, da hätte weder strtolower() noch mb_strtolower() etwas zu tun gehabt. Ich kann das Fehlerbild nur nachvollziehen, wenn der PHP-Code und somit das Stringliteral gemäß ISO-8859-1 kodiert ist und dem Browser gesagt wird, es käme UTF-8, beispielsweise durch die ini-Direktive default_charset.
Gib doch mal vor und nach dem strtolower() die Strings mit echo urlencode($str); aus. Damit sieht man die Kodierung der Umlaute sehr einfach.
Nun stelle ich mir aber die Frage, wie schnell ich mir Probleme damit einhandeln könnte,
Die bekommst du, wenn du dir über Zeichenkodierung zu wenig Gedanken machst. Prinzipiell muss zum einen ein verarbeitendes System mit der verwendeten Kodierung umgehen können, zum andern muss ein Nachfolgesystem die verwendete Kodierung mitgeteilt bekommen. Und die Zeichen müssen dementsprechen korrekt kodiert sein. Der Teufel steckt im Detail, wie man das den jeweiligen Systemen einzustellen beziehungsweise mitzuteilen hat.
Im Manual habe ich dann in den Kommentaren eine Funktion gefunden, die das ändert aber auch schon uralt ist und zudem den Nachteil hat, dass man auch alles damit konvertieren muss,
Die ist nicht alt, sondern prinzipbedingt nicht für alle Situationen geeignet, auch damals schon nicht. utf8_decode() muss alle Zeichen verwerfen, die in der Zielkodierung ISO-8859-1 nicht enthalten sind. Das kann man nur dann anwenden, wenn keine Zeichen außerhalb des Umfangs von ISO-8859-1 verarbeitet werden.
wobei ich nicht mal getestet habe was passiert, wenn kein UTF-8 vorliegt.
Dann geht es nicht, weil das dort verwendete utf8_decode() dann für UTF-8 ungültige Byte-Sequenzen findet und diese zu einem Fragezeichen umwandelt.
Na ja, dann fiel mir ein da war ja auch eine andere Möglichkeit, mb_strtolower().
Ich vermute mal, und das ist die eigentliche Frage hier, ich sollte immer diese anstatt strtolower() verwenden, oder gibt es Ausnahmen?
Das kommt immer darauf an, wie du dein System eingestellt hast, und welche Kodierung tatsächlich vorliegt und verarbeitet werden soll. Prinzipiell ist es jedoch empfehlenswert, alles auf UTF-8 einzustellen, also angefangen von Code-Dateien über Daten-Dateien und Datenbankinhalten, gehend über die gesamte Verarbeitungskette, bis hin zu den Ausgabekanälen.
Das ist auch keine Besonderheit der Datenverarbeitung. Wenn für Lebensmittel die Verarbeitung falsch stattfindet oder die Kühlkette unterbrochen wird, entsteht unter Umständen auch ein unbrauchbares Ergebnis.
Denn normalerweise warnt das Manual plakativ doch vor veralteten/nicht_sinnvollen Sachen, daher der Gedanke es gibt vielleicht doch manchmal Gründe strtolower den Vorzug zu geben?
Die Funktionen sind ja auch nicht an sich veraltet, sondern nur auf eine bestimmte Kodierung ausgelegt. Man kann aber sagen, dass diese ISO-8859-Kodierungen nicht mehr zeitgemäß sind.
Und wenn das so ist, auch immer mit dem Argument UTF-8
mb_strtolower($str, 'UTF-8');, oder spricht da was dagegen?
Der Aufwand. Man kann den Multibyte-Funktionen mit mb_internal_encoding() generell mitteilen, welche Kodierung es zu erwarten hat sowie verwenden soll.
dedlfix.
Hallo dedlfix,
Nun weiss ich zwar, dass strtolower keine Umlaute umwandeln kann, hatte aber erwartet, dass diese dann dennoch normal erscheinen.
Du hast da wohl einen Fehler im Versuchsaufbau. Die betroffenen Umlaute sind ja bereits Kleinbuchstaben, da hätte weder strtolower() noch mb_strtolower() etwas zu tun gehabt. Ich kann das Fehlerbild nur nachvollziehen, wenn der PHP-Code und somit das Stringliteral gemäß ISO-8859-1 kodiert ist und dem Browser gesagt wird, es käme UTF-8, beispielsweise durch die ini-Direktive default_charset.
Da hätte ich jetzt eher vermutet, dass strtolower auch nicht damit zurecht kommt, wenn es Umlaute in Großschrift oder Kleinschrift sind, sozusagen das gar nicht erkennen kann und dann nicht zu interpretieren weiss.
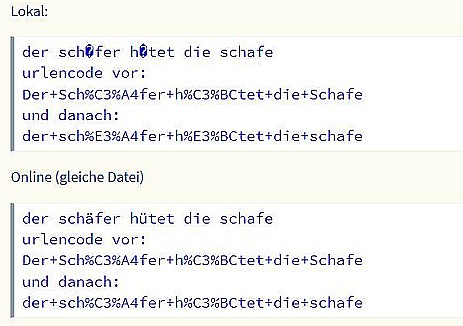
Aber es kommt noch seltsamer. Hatte das alles lokal probiert und nach euren Ausführungen "ist eigentlich so nicht möglich" das auch mal hochgeladen. Und siehe da (überrascht) Online funktioniert alles ohne Hieroglypen.
Lokal:
der sch�fer h�tet die schafe
urlencode vor:
Der+Sch%C3%A4fer+h%C3%BCtet+die+Schafe
und danach:
der+sch%E3%A4fer+h%E3%BCtet+die+schafe
Online (gleiche Datei)
der schäfer hütet die schafe
urlencode vor:
Der+Sch%C3%A4fer+h%C3%BCtet+die+Schafe
und danach:
der+sch%C3%A4fer+h%C3%BCtet+die+schafe
Gib doch mal vor und nach dem strtolower() die Strings mit
echo urlencode($str);aus. Damit sieht man die Kodierung der Umlaute sehr einfach.
Bin nicht sicher wie du das jetzt meinst. Habe urlencode genutzt und bei der lokalen Variante ist es halt %E3%A4, was anscheinend kein zuzuordnendes Zeichen ist.
Bin mir aber auch nicht sicher, dass das hier bei jedem gleich angezeigt wird, daher nochmal ein Screenshot:
Prinzipiell muss zum einen ein verarbeitendes System mit der verwendeten Kodierung umgehen können, zum andern muss ein Nachfolgesystem die verwendete Kodierung mitgeteilt bekommen. Und die Zeichen müssen dementsprechen korrekt kodiert sein. Der Teufel steckt im Detail, wie man das den jeweiligen Systemen einzustellen beziehungsweise mitzuteilen hat.
Scheint so, denn obwohl alle Dateien UTF-8 sind, Browser unicode anzeigt, sollte man doch meinen dürfte keine Probleme geben. Offenbar aber doch, wenn der Buchstabensalat nur auf der lokalen Version passiert.
Gruss
Henry
Tach!
Aber es kommt noch seltsamer. Hatte das alles lokal probiert und nach euren Ausführungen "ist eigentlich so nicht möglich" das auch mal hochgeladen. Und siehe da (überrascht) Online funktioniert alles ohne Hieroglypen.
Lokal:
der sch�fer h�tet die schafe urlencode vor: Der+Sch%C3%A4fer+h%C3%BCtet+die+Schafe und danach: der+sch%E3%A4fer+h%E3%BCtet+die+schafe
Hier sehen wir, dass das System die Bytes der UTF-8-Sequenz einzeln gemäß ISO-8859-1 interpretiert und das C3 (Ã) nach E3 (ã) konvertiert. A4 (¤) und BC (¼) sind keine Buchstaben und werden nicht bearbeitet. Das Ergebnis enthält an den Stellen keine gültigen UTF-8-Sequenzen mehr, weswegen der Browser das � anzeigt.
Online (gleiche Datei)
der schäfer hütet die schafe urlencode vor: Der+Sch%C3%A4fer+h%C3%BCtet+die+Schafe und danach: der+sch%C3%A4fer+h%C3%BCtet+die+schafe
Hier fand keine Umwandlung statt. Gemäß Handbuch
"Note that 'alphabetic' is determined by the current locale."
gibt es anscheinend auf dem System keine locale-Konfiguration, die für die Nicht-ASCII-Zeichen entsprechende Regeln enthält.
Bei meinem Versuch verhielt sich das System wie bei dir das Online-System, also ohne locale für die betroffenen Zeichen. Um die � hinzubekommen, hatte ich mir ein Szenario vorgestellt, das mir zwar wahrscheinlich erschien, aber dann doch nicht bei dir der Fall war. Deine � hatten letztlich eine andere Ursache, die ich bei mir ebensowenig beobachtet hatte, wie du auf deinem Online-System.
dedlfix.
 TS
TS